


In 2026, the Open-Source vs Proprietary LLM decision is no longer just about model quality. It is a strategic choice that shapes your AI stack, from inference design and latency targets to GPU capacity, security controls, fine-tuning, RAG, and production scaling.
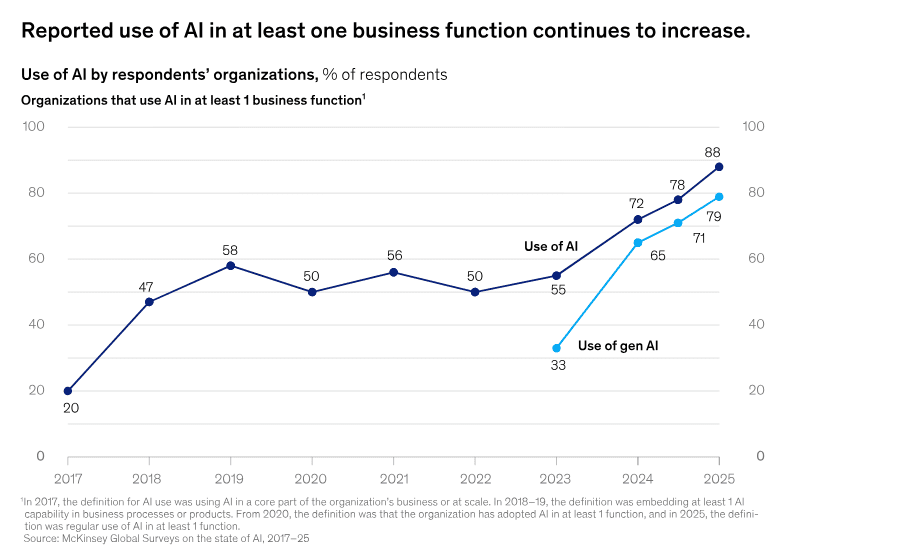
Enterprises are moving fast, but many are still stuck between AI experimentation and full-scale deployment. McKinsey reports that 88% of organizations use AI in at least one business function, yet only about one-third are scaling AI across the enterprise. That gap makes choosing the right LLM strategy critical.
- Open-source and open-weight models offer control, customization and private deployment.
- Proprietary LLMs offer managed access, vendor support and strong frontier performance.
This guide compares both approaches across cost, licensing, compliance, infrastructure, scalability, security, portability and business risk, helping AI leaders choose the right LLM strategy for real-world enterprise workloads.
Quick Answer: Open-Source vs Proprietary LLMs
For most enterprises, the right choice depends on workload sensitivity, AI maturity, cost model and infrastructure readiness.
| Choose This | When It Makes Sense |
|---|---|
| Proprietary LLM | You need speed, strong general reasoning and low infrastructure complexity. |
| Open-source/open-weight LLM | You need control, private deployment, fine-tuning and data residency. |
| Hybrid LLM strategy | You have mixed workloads across risk, cost, latency and compliance needs. |
What is an Open-Source or Open-Weight LLM?
Many models described as open-source are more accurately open-weight models. You may get model weights and some documentation, yet training data, full training code, evaluation data, acceptable-use rights, redistribution rights and unrestricted commercial rights may be limited by the license.
This distinction matters for enterprise teams.If you plan to fine-tune a model, embed it into a product, deploy it inside your VPC, redistribute model derivatives or expose it through a commercial service, you need to review the exact license and acceptable-use policy carefully.
Examples include Llama, Qwen, DeepSeek, Mistral, and Gemma. In practice, treat these as licensed AI assets with specific obligations around commercial use, redistribution, derivatives, prohibited use and attribution, even when the weights are downloadable.
What is a proprietary LLM?
A proprietary LLM is controlled by a vendor and usually consumed through a hosted API, enterprise platform, or managed AI service. You can test prompts and outputs, but you cannot inspect the model weights, training data, parameters, or internal architecture.
Examples include GPT, Claude, and Gemini. These models are typically accessed through API contracts, enterprise plans, or cloud-based AI platforms.
Proprietary LLMs are attractive because they reduce infrastructure complexity. The vendor handles model hosting, updates, performance improvements, documentation, platform security features and support, while the customer still owns application security, prompt/data governance, evaluation and integration design. However, teams must evaluate data handling, pricing, usage restrictions, model update policies, and vendor lock-in.
Difference Between Open-Source and Proprietary LLMs
The Open-Source vs Proprietary LLM comparison is not only about access. It affects deployment, customization, licensing, cost, data control, security, performance, support, portability and long-term flexibility.
The table below compares open-source/open-weight and proprietary LLMs across the factors that matter most for enterprise AI teams.
| Dimension | Open-Source / Open-Weight LLMs | Proprietary LLMs |
|---|---|---|
| Model access | Weights may be available for download or deployment | Access is usually through API or managed platform |
| Transparency | More visibility into model behavior, depending on release details | Limited visibility into weights, data, and architecture |
| Customization | Strong for fine-tuning, RAG, quantization, and domain adaptation | Limited to vendor-supported customization options |
| Deployment | Can run in cloud, private cloud, VPC, on-premises, or edge | Mostly vendor-hosted or platform-managed |
| Infrastructure | Requires GPU, storage, networking, monitoring, and MLOps | Vendor manages most infrastructure |
| Cost model | GPU, engineering, hosting, optimization, and maintenance costs | Token pricing, subscriptions, or enterprise contracts |
| Data control | Higher when privately deployed | Depends on vendor terms and data policies |
| Security | More control, but more responsibility | Managed controls, but less independent auditability |
| Performance | Strong for tuned, private, or domain-specific workloads | Often strong for frontier reasoning and broad tasks |
| Support | Community, internal teams, or paid partners | Vendor-backed support and SLAs |
| Lock-in | Lower with portable architecture | Higher when workflows depend on one vendor API |
| Best fit | Private, customized, high-volume, or regulated workloads | Fast deployment, general reasoning, and low-ops adoption |
OpenRouter’s 2025 State of AI study analyzed more than 100 trillion tokens across its own platform and found that proprietary models still served most tokens, while open-weight models grew to approximately one-third of usage by late 2025.
Note: This is OpenRouter platform data, not a full global market estimate, but it shows meaningful production adoption of open models.
Key Takeaways:
- Open-source and open-weight LLMs can give teams more control over deployment, customization and data privacy when the model license, infrastructure and governance model support those goals.
- Proprietary LLMs reduce operational effort through hosted access, managed reliability, and vendor support.
- Open models are not automatically cheaper because infrastructure and engineering costs still matter.
- Proprietary models are easier to start with, but can create cost and lock-in challenges at scale.
Which is More Cost-Effective: Open-Source or Proprietary LLMs?
Cost is one of the most important decision factors for teams. But the comparison is not as simple as ‘open-source is cheaper’ and ‘proprietary is expensive.’
- Open-source and open-weight LLMs may reduce dependency on vendor API pricing, but they introduce infrastructure costs. Teams need to account for GPU instances, storage, networking, inference servers, orchestration, autoscaling, monitoring, evaluation, security reviews, incident response and engineering time.
- Proprietary LLMs are often cheaper and easier to start with because teams can use APIs without managing infrastructure. However, costs can rise quickly with high-volume inference, long context windows, AI agents, repeated tool calls, and production-scale traffic.
The better metric is cost per successful task, not only cost per token. A cheaper model is not truly cheaper if it produces lower-quality outputs, more hallucinations, unsafe actions, slower responses, higher escalation rates or more manual review.
Buyer Note: ‘Compare total cost of ownership across token pricing, GPU cost, engineering effort, latency, reliability, output quality, and scaling needs.’
Which Option is Safer for Security, Privacy, and Compliance?
Neither open-source nor proprietary LLMs are automatically safer. Security depends on deployment design, governance, data flow, access control, vendor terms, and internal operational maturity.
Open-source and open-weight LLMs can give teams stronger control over data residency, private inference, logging, auditability, and access policies. This is valuable for regulated industries such as finance, healthcare, legal, public sector, and enterprise SaaS.
However, this control also comes with responsibility. Teams must manage infrastructure hardening, vulnerability management, prompt injection risks, model safety testing, compliance documentation, and incident response.
Proprietary LLMs may offer enterprise-grade security features, admin controls, compliance certifications, and vendor-managed governance. But teams must carefully review data retention policies, training usage, prompt logging, regional processing, and audit rights.
Practical Takeaway:The safer option is not defined by whether the model is open or closed. It is defined by how well the model fits your data sensitivity, compliance needs, governance maturity, and risk controls.
Which Performs Better: Open-Source or Proprietary LLMs?
Performance depends on the workload, evaluation dataset, model version, prompt design, context length, latency target and serving stack.
- Proprietary LLMs often perform well on frontier reasoning, complex coding, multimodal tasks, long-context workflows, and broad general-purpose use cases. Vendors continuously update these models behind managed APIs, which can make them attractive for teams that need strong out-of-the-box performance.
- Open-source and open-weight models can perform better in narrow or domain-specific workflows after fine-tuning, RAG, quantization, prompt optimization, or inference tuning. For example, a fine-tuned open model connected to a strong internal knowledge base may outperform a general proprietary model for customer support, compliance search, or product documentation.
Teams should avoid choosing models based only on public benchmarks because benchmark performance may not match private data, latency constraints, tool use, safety needs or cost targets. Instead, they should test models on real prompts, actual user journeys, expected latency targets, hallucination rates, cost per successful task, and compliance requirements.
Benchmarking checklist:
- Model version
- Evaluation date
- Prompt set
- Context length
- Hallucination rate
- Latency
- Cost per task
- RAG quality
- Fine-tuning results
- Fallback performance
When to Choose Open-Source?
Open-source and open-weight LLMs are a strong fit when control, customization, and private deployment matter more than convenience.
They are especially useful when teams need to:
- Fine-tune models for domain-specific workflows.
- Run inference in a private cloud, a VPC, or an on-premises environment.
- Keep sensitive data under internal control.
- Reduce long-term dependency on a single vendor.
- Customize RAG, latency, context handling, and model behavior.
- Build differentiated AI products rather than relying solely on shared APIs.
- Optimize high-volume inference costs when GPU utilization, batching, quantization and serving efficiency are strong enough to beat API economics.
For example, a healthcare company may prefer private deployment to protect patient data. A financial services firm may need stricter auditability and data residency. A SaaS company may want to fine-tune or ground an open-weight model on product documentation or customer-support history, but it must handle privacy, consent, retention and data-leakage risks.
When to Choose Proprietary?
Proprietary LLMs are a strong fit when teams need speed, simplicity, and vendor-backed reliability.
They are especially useful when teams need to:
- Launch AI features quickly.
- Avoid managing GPU infrastructure.
- Access strong general-purpose reasoning.
- Use mature APIs and documentation.
- Get vendor support and enterprise controls.
- Build prototypes before investing in private infrastructure.
- Support teams with limited MLOps or AI infrastructure expertise.
For product leaders, proprietary LLMs can shorten time to market. For AI leads, they provide a fast way to test use cases. For CTOs, they reduce the operational burden of model hosting, scaling, patching and performance tuning, but they do not remove the need for governance, evaluation, fallback and cost controls.
When to Choose a Hybrid LLM Strategy?
Hybrid is often the practical answer because enterprise workloads vary by risk and economics. You can route different tasks to different models while keeping governance consistent.
Most teams have a mix of workflows that do not share the same privacy or latency needs. Proprietary APIs can handle frontier reasoning and complex customer-facing tasks. Meanwhile, open-weight models can handle private RAG, internal summarization, and cost-sensitive automation at scale.
Additionally, hybrid can reduce lock-in if you keep interfaces stable, standardize evaluations and preserve the ability to swap providers or model versions behind a routing layer.
Example hybrid architecture
You can implement a hybrid strategy with a few standard components:
- Proprietary LLM for complex reasoning and broad general tasks
- Open model for internal RAG and private inference inside your VPC
- Fine-tuned open-weight model for domain-specific workflows
- Model router with policy rules and cost controls
- Evaluation layer with offline and online tests
- Governance layer for logging, approvals, and red teaming
- Fallback model for outages and budget enforcement
- Cost and latency monitoring tied to user journeys
How to Choose the Right LLM Strategy?
The right LLM strategy depends on workload type, risk level, data sensitivity, internal AI maturity, infrastructure readiness, budget, latency target and compliance needs.
Use this decision matrix as a practical starting point:
| Business Need | Recommended Approach |
|---|---|
| Fast prototype | Proprietary LLM |
| Private data workflow | Open-source or open-weight LLM |
| High-volume inference | Open-source or hybrid |
| Complex reasoning | Proprietary or hybrid |
| Domain-specific workflow | Fine-tuned open-weight model |
| Regulated workload | Private open model or carefully reviewed enterprise API |
| Low MLOps maturity | Proprietary LLM |
| Strong infrastructure team | Open-source or hybrid |
| Vendor lock-in concern | Open-source or hybrid |
| Customer-facing reliability | Proprietary or hybrid with fallback |
| Cost-sensitive repetitive task | Open-source or open-weight LLM |
| Need for vendor support | Proprietary LLM |
A practical evaluation process should include model performance, deployment design, security requirements, licensing terms, latency targets, fallback options, governance controls, and total cost of ownership.
Choose the Right LLM Strategy with AceCloud
The open-source/open-weight vs proprietary LLM decision comes down to how your enterprise balances control, cost, performance, compliance, licensing, portability and deployment complexity.
Open-source and open-weight models are ideal when you need private inference, fine-tuning, RAG customization, data control and lower dependency on vendor APIs. Proprietary LLMs are better when speed, managed access and frontier performance matter most. For many teams, a hybrid approach is the most practical path.
But the model is only one part of the decision. Your infrastructure determines how well that model performs in production.
AceCloud helps AI teams run open, proprietary or hybrid LLM workloads with cloud GPU infrastructure, managed Kubernetes, secure networking and scalable compute for inference, fine-tuning and production AI deployment.
Whether you are building private RAG, deploying open-weight models, scaling inference workloads or evaluating hybrid AI architecture, AceCloud can help you design the right foundation. Need clarity on the right LLM setup for your workloads? Book a free consultation with AceCloud today.
Frequently Asked Questions:
Open-source or open-weight LLMs can provide more access and control, including local/private deployment, fine-tuning and private inference, depending on the license and release details. Proprietary LLMs are controlled by vendors and are usually accessed through an API or managed platform.
Open-source LLMs can be cheaper at scale if teams can efficiently manage GPU infrastructure and engineering costs. Proprietary LLMs are often cheaper at the start because they avoid infrastructure setup, but they can become expensive with high-volume usage, long context and repeated agentic workflows.
Neither is automatically safer; the safer option depends on architecture, data handling, controls and operational maturity. Security depends on deployment design, access controls, logging, data retention, model governance, compliance requirements and continuous risk monitoring.
Proprietary LLMs often perform better on frontier reasoning, broad general tasks, complex coding and multimodal workflows, but this should be validated against your private evaluation set. Open-weight models can perform better in narrow or domain-specific workflows after RAG, fine-tuning and inference optimization.
Yes. A hybrid strategy often fits enterprise reality because different workloads have different privacy, cost, latency, capability, regulatory and performance needs. Teams can use proprietary models for complex tasks and open models for private or cost-sensitive workloads.
An open-weight LLM is a model where the weights are available for download or deployment, but the model may not be fully open-source. Training data, source code, commercial rights and redistribution permissions may still be restricted by the license.
A company should self-host an LLM when it needs stronger data control, private inference, custom fine-tuning, lower long-term vendor dependency, lower cost at high utilization or tighter control over latency and deployment architecture.
Open-source/open-weight LLM deployment usually requires GPU/accelerator compute, storage, networking, inference servers, orchestration, autoscaling, monitoring, security controls, cost tracking, model registry, evaluation pipeline and incident-response readiness.

