The most important thing about Claude Opus 4.8 may not be that it is smarter. It may be that it is easier to delegate work to. That sounds less exciting than a benchmark jump, right? But bear with us.
The industry is moving from models that answer questions to models that actually execute tasks. And once AI starts doing real work on your behalf, raw intelligence stops being the main thing that matters.
The model has to stay on track. It must check its own work. It must know when it is uncertain. And it must stop pretending a task is finished when it is not.
That is exactly what makes Claude Opus 4.8 worth paying attention to.
The obvious question after any model release is whether it beats GPT or Gemini on benchmarks. The better question is what kind of work Anthropic is preparing Claude to do next. From that angle, Opus 4.8 looks less like a chatbot upgrade and more like a serious agent upgrade.
Anthropic’s own launch messaging points in this direction.
The company says Opus 4.8 improves coding, agentic skills, reasoning, and practical knowledge work. It also launched dynamic workflows for Claude Code, where Claude can plan large tasks, run parallel subagents, and verify outputs before reporting back.
That is the real story here. Not better answers. Better delegation.
AI Is Moving Past the Chat Window
Most people still use AI in a simple loop.
You type something, it responds, and you decide what to do next. You are always in control. The model is basically a fast research assistant you keep nudging in the right direction.
But the industry has been shifting toward something more ambitious.
Agentic AI is where the model does not just answer a question but actually works through a task. It researches, writes and runs code, navigates software, debugs errors, updates its own plan, and keeps going across multiple steps without needing you to check in every few minutes.
In theory, that is the dream. In practice, however, it has been frustrating enough that most teams either end up babysitting the agent anyway or quietly abandon the workflow.
You give the system a task, but you still have to watch whether it skipped a step, misread the goal, made an assumption it should not have, or confidently reported success before the work was actually done.
That gap between ‘impressive demo’ and ‘reliable delegation’ is exactly where Claude Opus 4.8 becomes important. The bottleneck holding agentic AI back is no longer ambition. It is reliability.
The Real Problem With AI Agents Is Not Intelligence
Most people assume AI agents fail because the model is not smart enough. Sometimes that is true, but most agent failures are not intelligence failures. They are reliability failures.
Here is where the gaps usually show up.
| What Goes Wrong | Why It Matters |
|---|---|
| Agent says a task is done when it is not | You lose trust and end up verifying everything manually |
| Skips checking assumptions | Early mistakes compound into bigger failures down the line |
| Loses track of the original goal | Long workflows drift away from what you actually wanted |
| Produces confident but wrong outputs | Errors are harder to catch because they look polished |
| Fails to debug its own work | Treats the first draft as the final answer |
A model can be genuinely impressive in a chat window and fall apart the moment you hand it a 50-step workflow.
Chat rewards fluency. Agents require endurance.
A chatbot can get away with one great answer. An agent has to make dozens of decisions over time, and each one shapes the next.
Small mistakes accumulate. A skipped verification in the middle of a workflow can silently break the whole result.
A 2026 report from TechTarget on agentic AI governance puts this plainly: the key issue is no longer whether AI agents can automate work, but whether operational reliability is in place to handle autonomous systems at scale.
That is why the most valuable agent models will not simply be the ones that sound smartest. They will be the ones that stay useful after the tenth step, the thirtieth step, and the fiftieth step.
What is Anthropic Optimizing With Claude Opus 4.8
The themes Anthropic keeps coming back to with this release are not about raw performance scores. They are about the qualities that make AI safe to hand real work to.
Self-verification is the first one.
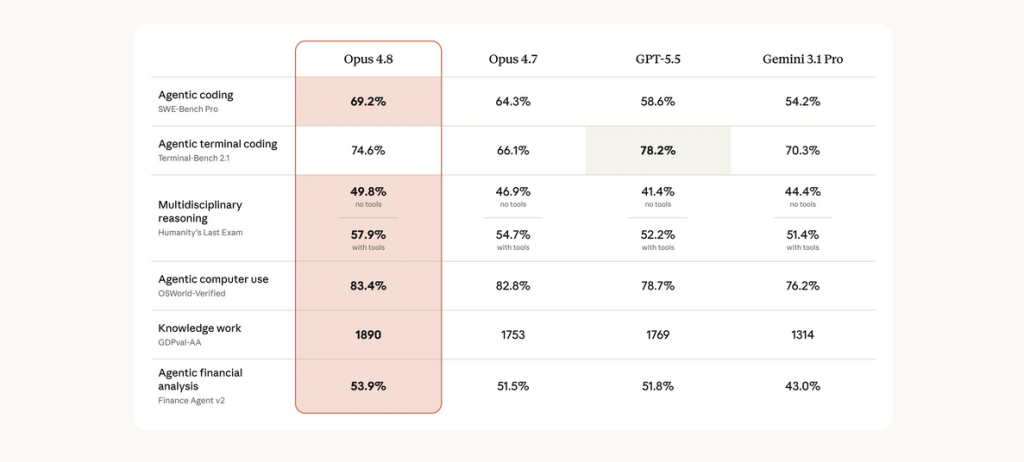
For agents, checking work is not optional. It is the foundation of trust. If a coding agent modifies a codebase, it needs to inspect the consequences of its own changes. If a research agent produces a report, it needs to distinguish between sourced facts and plausible guesses. Anthropic says dynamic workflows in Claude Code now verify outputs before reporting back. That matters because verification is what turns activity into dependable execution.
Honest uncertainty signaling is the second one
When a chatbot guesses, you can usually catch it. When an agent guesses inside a longer workflow, the mistake may be buried several steps deep by the time it surfaces. Anthropic says Opus 4.8 is around four times less likely than Opus 4.7 to let flaws in its own code pass without comment.
For real-world work, ‘I am not sure’ is often more valuable than a confident wrong answer.
The tradeoff, of course, is that more careful agentic work can require more compute, more tokens, and more patience. But that is exactly the point: reliable delegation is not just about faster answers. It is about fewer hidden failures.
Long-horizon consistency is the third
A single chat response takes seconds. Real agent workflows can run for minutes or hours, requiring the model to remember the plan, adapt to new information, and keep the end goal in view across many decisions.
Recent research on this is striking. The SWE-EVO benchmark, which tests coding agents on long-running software evolution tasks, found that GPT-5 with OpenHands achieved only 21% on those tasks, compared with 65% on the more isolated SWE-Bench Verified benchmark.
That performance gap is the long-horizon problem in hard numbers.
What This Looks Like in Practice
Think about a research agent running overnight to produce a competitive analysis.
With a weaker model, you come back to a polished-looking report full of subtle errors because the agent filled gaps with confident guesses. With better uncertainty signaling, it flags those gaps instead.
The output may look less seamless, but it is far more trustworthy. You know exactly where to pay attention.
Now think about a coding agent refactoring a large codebase.
The failure mode is not usually that the model cannot write code. It is that the model changes one part of the system, breaks another, and does not notice.
SWE-Chain, which benchmarks agents on chained package upgrades across multiple releases, shows that agents still struggle when each upgrade builds on the codebase state produced by previous steps.
The winning model in that scenario is not the fastest code generator. It is the one that revisits assumptions, runs checks, catches regressions, and knows when the plan needs to change.
Or consider customer support automation at scale.
An agent may need to classify tickets, identify urgency, route requests, draft replies, and escalate edge cases across hundreds of cases. The business does not need one brilliant answer. It needs consistent judgment across the full run.
Long-horizon reliability is what makes that viable in production.
These are not edge cases. They are exactly the workflows companies are actively trying to ship. And they are exactly where unreliable autonomy becomes expensive.
Why Benchmarks Will Not Tell You What You Need to Know
Benchmarks matter. They give the industry a shared way to compare models and track progress. But they do not fully answer the question businesses actually care about.
If you are deploying AI agents on real workflows, you are not asking whether Claude Opus 4.8 can solve a logic puzzle. You are asking whether it can finish a messy, 50-step task without creating a mistake you do not catch until it has already caused a downstream problem.
Traditional benchmarks test peak performance on bounded, well-defined problems. Agent work is messier. It involves incomplete information, changing context, tool use, and decisions that depend on previous steps.
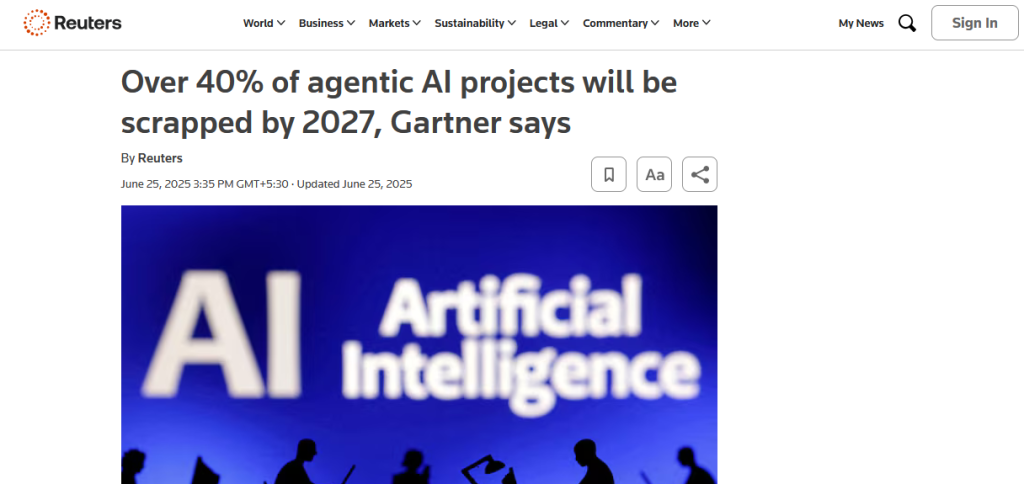
A model that looks great on a leaderboard can still behave unpredictably in production. This is not a theoretical concern either. Reuters reports predictions of over 40% of agentic AI projects being canceled by the end of 2027 due to escalating costs, unclear business value, and inadequate risk controls.
Here is a more useful frame.
Think about what you actually lose when an agent fails mid-task. Time to restart, cost of the failed run, and in some cases, downstream damage from outputs that looked correct but were not.
The models that reduce those failure rates are worth more in practice than models that score slightly higher on a benchmark but fail when it counts.
Intelligence gets you in the door. Reliability is what keeps you there.
The Bigger Shift with Claude Opus 4.8
The first era of AI competition was about fluency. Could the model generate coherent language? The second era was about reasoning. Could it solve hard problems?
The third era, the one we are stepping into now, is about dependable execution. Can you trust the model to do real work on your behalf?
That shift changes what we should be looking for when evaluating a model release.
The important question is no longer just whether a new model is smarter. It is whether the model is safer to trust with responsibility.
Claude Opus 4.8 is Anthropic’s clearest signal yet that they understand what this era requires. Its most interesting improvements are not only in what the model can produce, but in how it behaves while working.
Whether it checks itself. Whether it flags uncertainty. Whether it can carry a task through to completion without quietly going off the rails.
That is what agents need. And it is what chatbots never had to be good at.
That is why Claude Opus 4.8 deserves attention beyond benchmark comparisons. The real question is not whether it gives better chat responses. It is whether it makes AI easier to trust with actual work.
If the next era of AI is about delegation, then reliability is not a side feature. It is the product.