RAG pipelines break in production. But not dramatically. There will be no loud errors, no obvious crashes. They just quietly degrade. Retrieval quality drops. Embeddings go stale. Vector indexes bloat up. And by the time someone notices, your LLM is confidently answering questions with outdated or corrupted context.
If you’re running a RAG system at any meaningful scale, you already know this pain. The question is: what do you do about it? This post walks through how to build an autonomous self-healing system that combines Snowflake’s observability capabilities with Postgres’s operational strengths.
Why RAG Pipelines Degrade?
Before getting into the solution, it’s worth understanding what actually goes wrong. RAG systems have a few moving parts that break in predictable ways:
1. Stale embeddings
Your source documents change. New products launch, policies update, content gets rewritten. But if your embedding pipeline doesn’t pick up those changes, your vector store is serving outdated representations. Retrieval scores look fine on paper. The answers are just wrong.
2. Index drift
Postgres indexes, including pgvector HNSW and IVFFlat indexes, degrade with writes. Every insert, update, and delete shifts the index slightly out of optimal shape. After enough of them, retrieval latency climbs and recall drops.
3. Dead tuple bloat
Postgres doesn’t delete rows immediately. It marks them dead and cleans them up during VACUUM. If autovacuum can’t keep up, which happens during heavy write workloads, dead tuples pile up, tables bloat, and query performance suffers.
4. Chunk-level inconsistencies
Documents get partially re-ingested. Chunks from old versions coexist with chunks from new ones. Your retrieval returns a mix of stale and fresh context, and your LLM has no way to know the difference.
None of these are catastrophic on their own. Combined, over weeks of production traffic, they’re enough to quietly kill your retrieval quality. Reactive maintenance, where someone notices retrieval is bad, files a ticket, and someone runs a fix, is too slow. You need the system to fix itself.
Understanding Snowflake Postgres Architecture
Snowflake acts as the observability and metadata layer. It continuously ingests telemetry from your RAG pipeline, for instance, query latency, retrieval hit rates, embedding staleness scores, and chunk freshness timestamps. It aggregates that data, runs anomaly detection, and flags health issues.
Postgres (with pgvector) is where your actual RAG data lives, i.e., the chunks, the embeddings, the vector indexes. It also hosts the remediation logic, i.e., PL/pgSQL functions, scheduled jobs via pg_cron, and triggers that fire when health thresholds are breached.
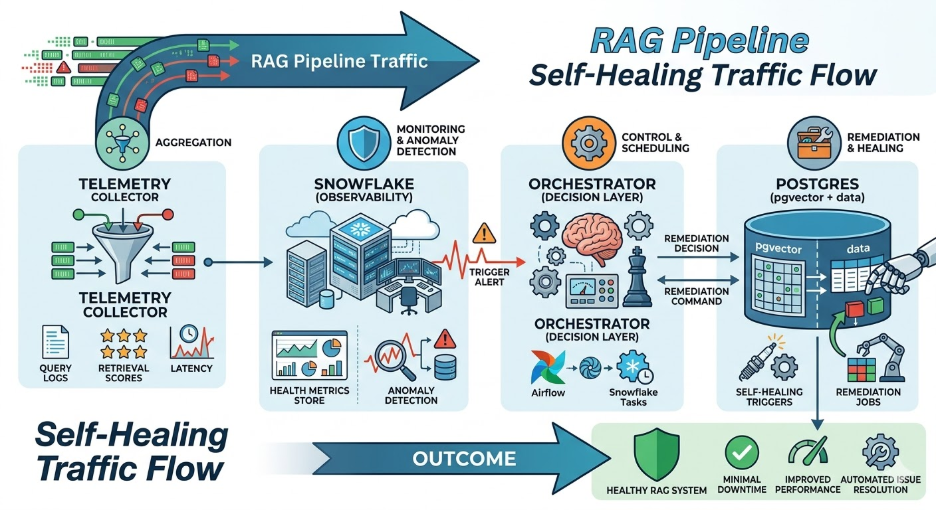
Image: RAG Pipeline Traffic
An orchestration layer, such as Airflow, Snowflake Tasks, or a simple Python scheduler, ties them together. It reads the health signals from Snowflake and kicks off the right remediation jobs in Postgres.
Let’s go further and build each piece of architecture.
Step 1: Set Up the Observability Layer in Snowflake
First, create a schema in Snowflake to store RAG health metrics.
CREATE DATABASE rag_ops;
CREATE SCHEMA rag_ops.health;
-- Core metrics table
CREATE TABLE rag_ops.health.pipeline_metrics (
recorded_at TIMESTAMP_NTZ DEFAULT CURRENT_TIMESTAMP,
collection_name VARCHAR(255),
avg_query_latency_ms FLOAT,
retrieval_hit_rate FLOAT, -- % of queries returning relevant chunks
avg_similarity_score FLOAT,
stale_chunk_count INT, -- chunks not refreshed in N days
index_bloat_ratio FLOAT, -- estimated bloat vs. ideal index size
dead_tuple_ratio FLOAT
);
-- Anomaly detection view
CREATE OR REPLACE VIEW rag_ops.health.anomalies AS
SELECT
collection_name,
recorded_at,
avg_query_latency_ms,
retrieval_hit_rate,
CASE
WHEN retrieval_hit_rate < 0.70 THEN 'LOW_HIT_RATE'
WHEN avg_query_latency_ms > 500 THEN 'HIGH_LATENCY'
WHEN stale_chunk_count > 1000 THEN 'STALE_EMBEDDINGS'
WHEN index_bloat_ratio > 1.5 THEN 'INDEX_BLOAT'
WHEN dead_tuple_ratio > 0.20 THEN 'DEAD_TUPLE_BLOAT'
ELSE NULL
END AS anomaly_type
FROM rag_ops.health.pipeline_metrics
WHERE recorded_at >= DATEADD('hour', -24, CURRENT_TIMESTAMP)
HAVING anomaly_type IS NOT NULL; Next, set up a Snowflake Task to aggregate metrics on a schedule:
CREATE OR REPLACE TASK rag_ops.health.aggregate_metrics
WAREHOUSE = compute_wh
SCHEDULE = '15 minute'
AS
INSERT INTO rag_ops.health.pipeline_metrics
(collection_name, avg_query_latency_ms, retrieval_hit_rate,
avg_similarity_score, stale_chunk_count)
SELECT
collection_name,
AVG(query_latency_ms),
SUM(CASE WHEN similarity_score > 0.75 THEN 1 ELSE 0 END)::FLOAT / COUNT(*),
AVG(similarity_score),
COUNT(CASE WHEN DATEDIFF('day', last_embedded_at, CURRENT_DATE) > 7 THEN 1 END)
FROM rag_ops.health.raw_query_logs
WHERE logged_at >= DATEADD('minute', -15, CURRENT_TIMESTAMP)
GROUP BY collection_name;
ALTER TASK rag_ops.health.aggregate_metrics RESUME; Your telemetry collector (typically a thin Python wrapper around your RAG query path) pushes raw query logs into raw_query_logs. The task aggregates every 15 minutes. The anomaly view flags what needs attention.
Step 2: Configure Postgres for Self-Healing
On the Postgres side, you need three things: a health check mechanism, remediation functions, and a scheduler to run them.
Install pg_cron
-- In your Postgres instance
CREATE EXTENSION IF NOT EXISTS pg_cron;
CREATE EXTENSION IF NOT EXISTS vector; -- pgvector Create a Health Status Table
CREATE TABLE rag_health_log (
id SERIAL PRIMARY KEY,
checked_at TIMESTAMPTZ DEFAULT NOW(),
collection_name TEXT,
check_type TEXT,
status TEXT, -- 'ok', 'degraded', 'remediated'
detail JSONB
); Write the Core Health Check Function
CREATE OR REPLACE FUNCTION check_rag_collection_health(p_collection TEXT)
RETURNS TABLE(check_name TEXT, status TEXT, detail TEXT)
LANGUAGE plpgsql AS $$
DECLARE
v_dead_ratio FLOAT;
v_index_size BIGINT;
v_live_tuples BIGINT;
BEGIN
-- Check dead tuple ratio
SELECT
n_dead_tup::FLOAT / NULLIF(n_live_tup + n_dead_tup, 0)
INTO v_dead_ratio
FROM pg_stat_user_tables
WHERE relname = p_collection;
IF v_dead_ratio > 0.20 THEN
check_name := 'dead_tuples';
status := 'degraded';
detail := format('dead ratio = %.2f%%', v_dead_ratio * 100);
RETURN NEXT;
END IF;
-- Check index bloat (simplified estimate)
SELECT
pg_relation_size(indexrelid)
INTO v_index_size
FROM pg_stat_user_indexes
WHERE relname = p_collection
ORDER BY pg_relation_size(indexrelid) DESC
LIMIT 1;
IF v_index_size > 500 * 1024 * 1024 THEN -- > 500MB triggers rebuild check
check_name := 'index_size';
status := 'degraded';
detail := format('index size = %s MB', v_index_size / 1024 / 1024);
RETURN NEXT;
END IF;
-- Check stale embeddings
EXECUTE format('
SELECT COUNT(*) FROM %I
WHERE embedded_at < NOW() - INTERVAL ''7 days''
', p_collection) INTO v_live_tuples;
IF v_live_tuples > 1000 THEN
check_name := 'stale_embeddings';
status := 'degraded';
detail := format('%s chunks need re-embedding', v_live_tuples);
RETURN NEXT;
END IF;
END;
$$; Write Remediation Functions
-- Auto-vacuum and reindex
CREATE OR REPLACE FUNCTION heal_collection(p_collection TEXT)
RETURNS VOID LANGUAGE plpgsql AS $$
BEGIN
-- Run VACUUM ANALYZE
EXECUTE format('VACUUM ANALYZE %I', p_collection);
-- Log it
INSERT INTO rag_health_log (collection_name, check_type, status, detail)
VALUES (p_collection, 'vacuum', 'remediated',
jsonb_build_object('action', 'VACUUM ANALYZE', 'ts', NOW()));
-- Rebuild vector index if needed
EXECUTE format('
REINDEX INDEX CONCURRENTLY %I_embedding_idx
', p_collection);
INSERT INTO rag_health_log (collection_name, check_type, status, detail)
VALUES (p_collection, 'reindex', 'remediated',
jsonb_build_object('action', 'REINDEX CONCURRENTLY', 'ts', NOW()));
END;
$$;
-- Re-embed stale chunks (calls your embedding service)
CREATE OR REPLACE FUNCTION queue_stale_chunks_for_reembedding(
p_collection TEXT,
p_staleness_days INT DEFAULT 7
)
RETURNS INT LANGUAGE plpgsql AS $$
DECLARE
v_count INT;
BEGIN
EXECUTE format('
UPDATE %I
SET embedding_status = ''pending''
WHERE embedded_at < NOW() - ($1 || '' days'')::INTERVAL
AND embedding_status != ''pending''
', p_collection) USING p_staleness_days;
GET DIAGNOSTICS v_count = ROW_COUNT;
INSERT INTO rag_health_log (collection_name, check_type, status, detail)
VALUES (p_collection, 'reembedding_queue', 'remediated',
jsonb_build_object('chunks_queued', v_count, 'ts', NOW()));
RETURN v_count;
END;
$$; Schedule with pg_cron
-- Run health checks every 30 minutes
SELECT cron.schedule(
'rag-health-check',
'*/30 * * * *',
$$
DO $$
DECLARE rec RECORD;
BEGIN
FOR rec IN (SELECT DISTINCT collection_name FROM rag_health_log
WHERE checked_at > NOW() - INTERVAL '1 hour'
UNION SELECT 'documents') -- your actual collection names
LOOP
IF EXISTS (
SELECT 1 FROM check_rag_collection_health(rec.collection_name)
WHERE status = 'degraded'
) THEN
PERFORM heal_collection(rec.collection_name);
PERFORM queue_stale_chunks_for_reembedding(rec.collection_name);
END IF;
END LOOP;
END;
$$ $$
); Step 3: Build the Predictive Maintenance Model
Thresholds are good for catching problems after they happen. Prediction catches them before.
Here’s a lightweight approach using Python and scikit-learn, pulling metrics from Snowflake:
import pandas as pd
from sklearn.ensemble import IsolationForest
from snowflake.connector import connect
def fetch_metrics(conn, collection: str, lookback_days: int = 30) -> pd.DataFrame:
query = f"""
SELECT
recorded_at,
avg_query_latency_ms,
retrieval_hit_rate,
stale_chunk_count,
index_bloat_ratio,
dead_tuple_ratio
FROM rag_ops.health.pipeline_metrics
WHERE collection_name = '{collection}'
AND recorded_at >= DATEADD('day', -{lookback_days}, CURRENT_TIMESTAMP)
ORDER BY recorded_at
"""
return pd.read_sql(query, conn)
def train_anomaly_detector(df: pd.DataFrame) -> IsolationForest:
features = [
'avg_query_latency_ms',
'retrieval_hit_rate',
'stale_chunk_count',
'index_bloat_ratio',
'dead_tuple_ratio'
]
model = IsolationForest(contamination=0.05, random_state=42)
model.fit(df[features].fillna(0))
return model
def predict_health(model: IsolationForest, df: pd.DataFrame) -> pd.DataFrame:
features = [
'avg_query_latency_ms',
'retrieval_hit_rate',
'stale_chunk_count',
'index_bloat_ratio',
'dead_tuple_ratio'
]
df = df.copy()
df['anomaly_score'] = model.decision_function(df[features].fillna(0))
df['is_anomaly'] = model.predict(df[features].fillna(0)) == -1
return df
# Usage
conn = connect(
user='your_user',
password='your_password',
account='your_account',
database='rag_ops',
schema='health'
)
df = fetch_metrics(conn, collection='documents')
model = train_anomaly_detector(df)
results = predict_health(model, df.tail(10)) # check last 10 intervals
print(results[['recorded_at', 'anomaly_score', 'is_anomaly']])
You can run this model on a schedule (every few hours), write its predictions back to Snowflake, and let the orchestrator act on them the same way it acts on threshold-based anomalies.
Step 4: Wire the Autonomous Remediation Loop
The orchestration layer is what ties Snowflake signals to Postgres actions. Here’s a minimal Airflow DAG:
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime, timedelta
import snowflake.connector
import psycopg2
default_args = {
'owner': 'rag-ops',
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
def fetch_anomalies():
conn = snowflake.connector.connect(
user=..., password=..., account=...,
database='rag_ops', schema='health'
)
cursor = conn.cursor()
cursor.execute("""
SELECT collection_name, anomaly_type
FROM anomalies
WHERE recorded_at >= DATEADD('hour', -1, CURRENT_TIMESTAMP)
""")
return cursor.fetchall()
def run_remediation(**context):
anomalies = context['ti'].xcom_pull(task_ids='fetch_anomalies')
if not anomalies:
print("No anomalies. All healthy.")
return
pg_conn = psycopg2.connect(
host=..., dbname=..., user=..., password=...
)
cursor = pg_conn.cursor()
for collection, anomaly_type in anomalies:
print(f"Healing {collection}: {anomaly_type}")
if anomaly_type in ('HIGH_LATENCY', 'INDEX_BLOAT', 'DEAD_TUPLE_BLOAT'):
cursor.execute("SELECT heal_collection(%s)", (collection,))
if anomaly_type == 'STALE_EMBEDDINGS':
cursor.execute(
"SELECT queue_stale_chunks_for_reembedding(%s, %s)",
(collection, 7)
)
pg_conn.commit()
cursor.close()
pg_conn.close()
with DAG(
dag_id='rag_self_healing',
default_args=default_args,
schedule_interval='@hourly',
start_date=datetime(2024, 1, 1),
catchup=False,
) as dag:
t1 = PythonOperator(
task_id='fetch_anomalies',
python_callable=fetch_anomalies
)
t2 = PythonOperator(
task_id='run_remediation',
python_callable=run_remediation,
provide_context=True
)
t1 >> t2 Every hour, the DAG checks Snowflake for anomalies and runs the corresponding Postgres remediation function. Every remediation is logged back to both rag_health_log in Postgres and (optionally) Snowflake for audit purposes.
Step 5: Handle the Embedding Refresh Pipeline
Queuing stale chunks is only half the job. You also need a worker that actually re-embeds them. Here’s a minimal Python worker:
import psycopg2
import openai # or your embedding provider of choice
def process_embedding_queue(pg_conn, batch_size: int = 100):
cursor = pg_conn.cursor()
# Fetch a batch of pending chunks
cursor.execute("""
SELECT id, content
FROM documents
WHERE embedding_status = 'pending'
ORDER BY embedded_at ASC
LIMIT %s
FOR UPDATE SKIP LOCKED
""", (batch_size,))
rows = cursor.fetchall()
if not rows:
return 0
ids = [r[0] for r in rows]
texts = [r[1] for r in rows]
# Call embedding API
response = openai.embeddings.create(
model="text-embedding-3-small",
input=texts
)
embeddings = [e.embedding for e in response.data]
# Update rows
for doc_id, embedding in zip(ids, embeddings):
cursor.execute("""
UPDATE documents
SET embedding = %s,
embedded_at = NOW(),
embedding_status = 'complete'
WHERE id = %s
""", (embedding, doc_id))
pg_conn.commit()
return len(ids) Run this worker as part of your remediation Airflow task, or as a separate lightweight service polling for embedding_status = ‘pending’ rows.
How Should You Test the System?
Before going to production, test that the self-healing loop actually works.
Simulate dead tuple bloat
-- Create a burst of updates to generate dead tuples
UPDATE documents SET content = content || ' ' WHERE id < 10000;
UPDATE documents SET content = content WHERE id < 10000;
-- Check: SELECT n_dead_tup FROM pg_stat_user_tables WHERE relname = 'documents';
-- Then verify that pg_cron triggers heal_collection() within 30 minutes Simulate stale embeddings
UPDATE documents
SET embedded_at = NOW() - INTERVAL '10 days'
WHERE id BETWEEN 1000 AND 2000;
-- Verify that queue_stale_chunks_for_reembedding fires and the worker picks them up
Simulate retrieval degradation: Drop a vector index manually, run some queries, and verify that the latency spike registers in Snowflake and triggers a reindex.
Key metrics to track during testing:
- MTTR (Mean Time to Recovery): How long from anomaly to remediation?
- Retrieval precision before and after healing: Does re-indexing actually improve recall?
- False positive rate: How often does the system heal something that didn’t need it?
Key Production Guardrails to Consider
Here are a few things that will trip you up if you skip them. Let’s discuss them in detail.
1. Rate-limit your remediation jobs
REINDEX CONCURRENTLY is safe, but it still consumes I/O. If you trigger it on every 15-minute check, you’ll saturate your disk during write-heavy periods. Add a cooldown: don’t re-run a remediation for the same collection within N hours of the last one.
-- Only heal if last remediation was > 4 hours ago
SELECT heal_collection(p_collection)
WHERE NOT EXISTS (
SELECT 1 FROM rag_health_log
WHERE collection_name = p_collection
AND status = 'remediated'
AND checked_at > NOW() - INTERVAL '4 hours'
); 2. Budget your Snowflake compute
Continuous metric aggregation adds up. Use a small warehouse (XS or S) for health tasks, and avoid running them during your peak query hours.
3. Keep an audit trail
Every automated action should be logged with a timestamp, the triggering anomaly, and the outcome. When something goes wrong (and it will), you need to know what the system did in the hours before.
4. Know when to page a human
Some problems can’t be auto-healed. Persistent low retrieval quality despite remediation, unexpected schema changes, or recurring anomalies within short windows should trigger a PagerDuty alert, not another VACUUM.
As data ecosystems grow, maintaining operational visibility and cost control becomes just as important as maintaining database health. Organizations managing large-scale analytics workloads often complement these practices with Expert Snowflake Implementation Solutions to optimize warehouse usage, automate monitoring processes, and ensure long-term platform performance across evolving business requirements.
Result of Self-Healing in Snowflake Postgres for RAG
Once you are done configuring, here are a few results you should check. By this point, your RAG pipeline should have:
- Continuous observability: Snowflake ingests query telemetry every 15 minutes and flags anomalies in near-real time.
- Predictive signals: An Isolation Forest model catches subtle degradation patterns before they cross threshold boundaries.
- Automated remediation: pg_cron and Airflow handle VACUUM, REINDEX, and embedding refresh without human involvement.
- Full audit logs: Every healing action is recorded in Postgres and Snowflake for compliance and debugging.
The shift here isn’t just operational. It’s a change in how you think about RAG reliability. Instead of waiting for your retrieval quality to drop and scrambling to fix it, you’ve built a system that treats health maintenance as a continuous background process.
That’s what makes this ‘autonomous.’ Not that it never needs human oversight. It does, especially early on. But the default state is a pipeline that heals itself, not one that waits to be fixed.
Frequently Asked Questions
Autonomous self-healing means the RAG system can automatically detect degradation, trigger remediation, and restore performance without waiting for manual intervention. In this setup, Snowflake identifies health issues through telemetry, while Postgres handles fixes such as reindexing, vacuuming, and re-embedding stale chunks.
RAG systems usually degrade because embeddings become outdated, vector indexes drift after frequent writes, dead tuples accumulate in Postgres, and older document chunks remain mixed with fresh ones. These issues rarely cause obvious failures, but they steadily reduce retrieval accuracy and increase latency.
Snowflake works well as the observability and analytics layer because it can collect, aggregate, and analyze large volumes of health telemetry. Postgres, especially with pgvector, is better suited for storing embeddings, running operational checks, and executing remediation logic close to the data.
The most useful signals include query latency, retrieval hit rate, similarity scores, stale chunk count, index bloat ratio, and dead tuple ratio. Tracking these metrics helps surface both obvious failures and gradual quality loss before end users notice incorrect answers.
Yes. pgvector indexes such as HNSW and IVFFlat can lose efficiency as inserts, updates, and deletes accumulate. Over time, this can increase retrieval latency and lower recall, which is why scheduled maintenance and selective reindexing are important in production RAG systems.
That depends on how often your source content changes. For fast-moving data such as product catalogs, support knowledge bases, or policy documents, daily or near-real-time refreshes may be necessary. For more stable content, a weekly refresh cycle may be enough, especially if you also track staleness thresholds.
Thresholds are a strong starting point because they are simple, explainable, and easy to operationalize. Machine learning becomes useful when you want to detect subtle degradation patterns, recurring anomalies, or multi-signal issues that do not cross a single static threshold.
You should add cooldown periods, audit logs, retry limits, and escalation rules before letting the system heal itself automatically. Some actions, such as repeated reindexing or large-scale embedding refresh jobs, can create extra load, so it is important to rate-limit them and alert a human when anomalies persist.