
IaaS (Infrastructure-as-a-Service) migration is the process of moving IT resources, applications and data from on-premises infrastructure to IaaS, a cloud computing model. Migrating AI Workloads to IaaS isn’t just cost-effective, it’s about unlocking agility, scalability and operational precision.
According to a recent survey, IaaS will account for 29 percent of the cloud market by 2030.
Most modern AI stacks are already cloud-based. Therefore, your migration plan should be too. Migrating to cloud infrastructure enables better GPU scheduling, MLOps standardization and access to high-throughput storage and networking.
In this guide, we will define roles and have a clear roadmap for migrating training, inference, data pipelines and MLOps to IaaS. Besides, we’ll consider critical design factors like Kubernetes orchestration, FinOps guardrails and GPU pricing strategies.
Key Outcomes to Define Before On-Prem to IaaS Migration
Before you migrate, you need measurable business goals and technical SLOs to steer decisions and verify outcomes.
Critical KPIs
You should define business metrics such as time-to-experiment and cost per training hour, along with SLOs for latency, availability and error budgets. Then tie these to model accuracy thresholds so you protect user experience while tuning infrastructure.
Operating Model
You should appoint a migration architect to oversee the discovery, design and planning phases. Then, decide whether you’ll go with a single cloud or a multicloud approach and create a risk-based sequence for your migration waves. Treat rollback as a crucial option and make sure to practice it before you scale up.
Pre-Migration Benchmarks
In our experience, you must capture these pre-migration benchmarks:
| Component | Metric | Description / Unit |
|---|---|---|
| GPU | Utilization (%) | Active GPU usage percentage |
| GPU Memory Used (GB) | Memory consumption per GPU | |
| Per-GPU Throughput (samples/sec) | Number of samples processed per second per GPU | |
| Compute Latency (Average / Tail) | Time taken per operation (e.g., forward/backward pass) | |
| PCIe/NVLink Bandwidth Usage | Interconnect bandwidth (GB/s) between GPUs or with CPU | |
| Temperature / TDP (%) | Time taken per operation (e.g., forward/backward pass) | |
| CPU | Utilization per Core (%) | CPU usage per logical core |
| Context-Switch Rate | Number of context switches per second | |
| Process CPU Time | Total CPU time consumed by the training process | |
| Storage | IOPS (Read/Write) | Input/output operations per second |
| Throughput (MB/s) | Data read/write rate | |
| Latency (Avg / Tail – 95/99th percentile) | Storage access latency | |
| Dataset Read Patterns | Proportion of sequential vs random reads | |
| Cache Hit Ratio | % of data served from cache instead of disk | |
| Network | Sustained Bandwidth (Mbps/Gbps) | Average data transfer rate |
| RTT / Jitter | Round-trip time & variation | |
| Packet Loss (%) | Fraction of dropped packets | |
| Peak Concurrent Connections | Max number of active network connections | |
| Shuffle Throughput | Data shuffled between nodes (during training) | |
| Orchestration | Job Start Time | Time when job was initiated |
| Pod Scheduling Latency | Time between pod creation and scheduling | |
| Queue Wait Time | Time spent waiting in the job queue | |
| Preemption / Retry Rates | Frequency of job interruptions or restarts | |
| Cost | Cost per Training Hour | Real-time cost (e.g., $/hour) |
| Cost per Inference | Cost per inference operation | |
| Recurring License / Maintenance Fees | Ongoing operational or software costs |
You will compare these benchmarks with post-cutover metrics to verify improvements and prevent regression. Moreover, cost control must be visible from day one because many organizations rank managing cloud expenditure as a top challenge.
How to Inventory AI Workloads, Data and Dependencies Up Front?
Precise inventory shortens migration time and prevents cross-service breakage transition phases.
Comprehensive Inventory
You need to start by making a comprehensive list of all your services, batch and streaming jobs, datasets and their dependencies. Then include data lineage, sensitive data indicators, model files, feature stores and inter-service connections.
Here, we’ve listed discovery tools that you can use to gather configurations, performance metrics and TCP dependencies, which will help you organize systems effectively for each migration wave:
1. Services
- Service Name
- Description of purpose (e.g., “inference API”, “data preprocessor”, “training job scheduler”)
- Environment (prod/dev/staging/test)
2. Container Images
- Image Name
- Tag (e.g., v1.2.3, latest, sha256)
- Container Runtime
- Docker / containerd
- Runtime Version (e.g., Docker 24.0.7, containerd 1.7.9)
3. Host System Information
- Operating System
- Distro name/version (e.g., Ubuntu 20.04.6 LTS)
- Kernel Version
- e.g., 5.15.0-105-generic
4. GPU and Compute Stack
- CUDA Version (e.g., 12.2)
- cuDNN Version (e.g., 8.9.7)
- GPU Driver Version (e.g., NVIDIA 535.113.01)
- NVIDIA Runtime Toolkit / Container Toolkit Version
5. Networking Hardware
- Installed NICs
- Vendor/Model (e.g., Mellanox ConnectX-6)
- Firmware Version
- Driver version (OS module level)
6. Storage Details
- Storage Type
- e.g., NFS, Object Storage (S3), block device, local SSD
- Filesystem Type
- e.g., ext4, xfs, zfs
- Mount Layout
- Path mappings, data directories, volume mounts
- Storage Usage & Allocation
- Disk usage per mount, overprovisioning info
7. Feature Store
- Location/Endpoint
- URI or path (e.g., Redis, Feast, custom DB)
- Storage Backend
- SQL / NoSQL / file-based
- Update Schedule
- Batch / streaming / event-driven
8. Model Artifact Registry
- Path / URI
- S3, GCS, MinIO, NFS, MLflow, etc.
- Artifact Size
- Per model/version
- Format
- .pt, .onnx, .pb, .pickle, etc.
- Versioning Strategy
- SHA / semantic version / time-based
9. Secrets & Credential Stores
- Vault Type
- HashiCorp Vault, AWS Secrets Manager, Kubernetes secrets, etc.
- Access Method
- Mounted secrets / API tokens / sidecar injectors
- Rotation Policy
- Static, periodic, on-demand
10. Data Sensitivity & Compliance
- Data Sources Classification
- Label as: PII, PHI, PCI, regulated, internal, public
- Masking or Encryption Applied?
- At-rest / in-transit / field-level
- Access Control
- RBAC/ABAC, IAM policies
- Compliance Frameworks
- HIPAA, GDPR, SOC 2, FedRAMP, etc.
Performance Profiles
When it comes to performance tracking, record GPU memory footprints (GB), per-GPU batch wall-time (s/step), gradient aggregation times and whether the workload requires NVLink / NVSwitch or RDMA/InfiniBand for efficient multi-GPU scaling.
Note model parallelism needs, NCCL config and the minimum network fabric bandwidth required to avoid communication bottlenecks.
Strategy Tags
When we talk about strategy tags, tag each workload as rehost, replatform, refactor or replace, then annotate drivers such as cost control, resilience or developer productivity. Plan for containerization because a large majority of organizations already use, pilot or evaluate Kubernetes.
Which Type of Migration Method to Use?
Choosing a suitable migration method depends on your business needs. Consider how much data you must move, whether this is your first migration and the level of change your teams can absorb. These answers help you select the most effective strategy.
Rehosting
Rehosting or lift and shift migration is the simplest way to move from on-premises to the cloud. It’s an excellent choice if you want to make minimal changes to your code and need a quick transition. However, don’t expect to reap many cloud-native benefits initially and plan a replatform wave later.
Refactoring
Refactoring, often referred to as rip and replace or redesign, takes more time and effort compared to simply rehosting. You have the flexibility to decide when you need features like cloud-native scale, autoscaling or microservices. Just make sure to allocate enough time and test coverage for it.
Replatform
Positioned between rehosting and refactoring, replatform changes parts of an application while preserving core elements. Many teams call it move and improve or revise. It is an ideal choice when you choose specific components (DB, inference) that can be moved to managed services to reduce ops burden.
Replacing
When it comes to making a switch, you can opt for it when the functionality becomes standardized and the SaaS option aligns with your data residency and compliance requirements.
What are the Steps for On-Prem to IaaS Migration?
Here, we’ve mentioned a practical step-by-step migration approach that will reliably guide your move from on-premises to the cloud.
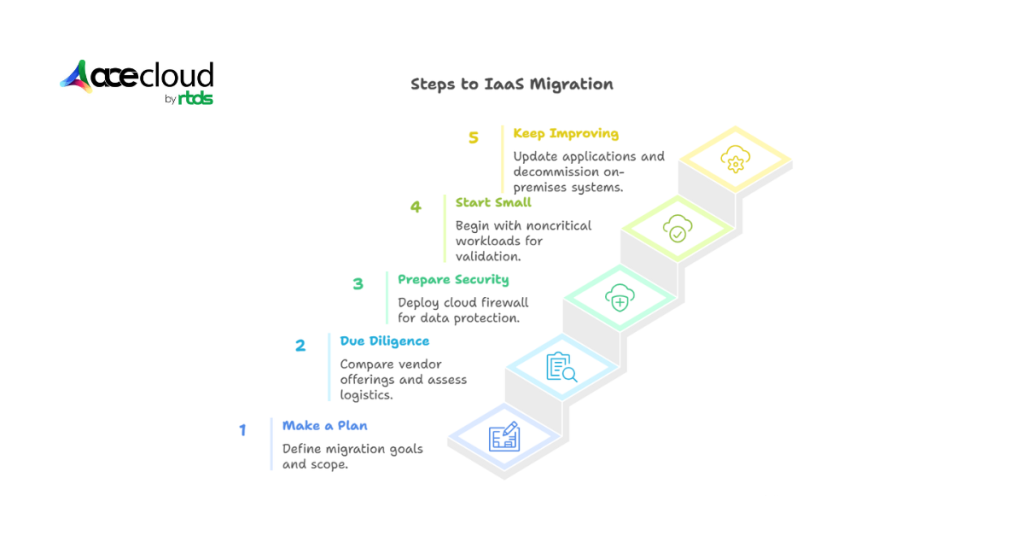
Make a Plan
Clarify why you are migrating and what you will move. Disaster recovery for a few apps is simpler than a full workload transfer. If DevOps is your primary driver, a move to PaaS may fit better than IaaS.
Build a complete inventory of applications and reports to find unused items or stale data so you avoid migrating what you do not need.
Do your Due Diligence
Compare vendor offerings to estimate total cost of ownership for each option. Assess logistics and staffing for lift and shift, replatforming or refactoring.
Starting small is highly advisable. For that, you can lift and shift first, then replatform or refactor once you understand your cloud requirements.
Prepare Your Security
When transferring large amounts of data, it’s important to prioritize secure methods. You should use encrypted tunnels like IPsec VPN or dedicated private connections such as AWS Direct Connect, Azure ExpressRoute or Google Cloud Interconnect to protect your data during transit.
Ensure that all application traffic is safeguarded by enforcing TLS on every connection.
To minimize exposure, segment your network and utilize Firewall as a Service (FWaaS) to secure both the cloud perimeter and your internal subnets. Just a heads up: FWaaS doesn’t cover on-premises environments, so make sure to use IPsec or a private link to secure that traffic.
Start Small
Begin with a noncritical workload and validate its behavior in the cloud. After confirming the app and data are sound, proceed with your chosen strategy.
Expect possible delays during the process, especially with refactoring that lacks thorough planning and testing in advance. Most providers offer tools that help reduce disruption.
Keep Improving
Synchronize and update applications after migration as needed. If you adopt a cloud-only approach, decommission on-premises systems. In many cases, retaining them remains valuable, such as when you run a hybrid cloud.
How to Design Networking and Landing Zone for Predictable Performance?
Design connectivity and guardrails first, so pilots behave like production and costs remain explainable.
Connectivity Choices
Start with site-to-site VPN for speed to first value, then plan private connectivity for production. Solutions such as partnered enterprise grade virtual firewalls provide more consistent latency and bandwidth than internet paths, which really help to reduce tail latency during training and inference processes.
Landing Zone Guardrails
Define VPC or VNet layout, subnets, route tables, firewalls, private endpoints and identity and access management (IAM) standards. Use policy to enforce controls by default, then layer service mesh if you need zero-trust east-west patterns. Provider landing zone guidance maps these decisions explicitly.
Throughput Awareness for AI
Make sure your network and cluster setup can keep up with the demands of your GPU servers and storage. High-performance nodes like NVIDIA H100 or A100, often used for distributed training, can generate multi-gigabit-per-second traffic depending on batch size, model parallelism or how frequently parameters are synchronized. To avoid bottlenecks, run a representative training job to understand your bandwidth needs, then design your storage and network to handle that load.
How Do You Optimise Post-Migration for Training and Inference Economics?
You can iterate on compute, storage and pricing models as your data and models change.
Tune and right-size
Adopt mixed precision where appropriate, shard or cache datasets closer to GPUs and refine autoscaling thresholds. Improve bin-packing on Kubernetes through node affinity, topology spread and GPU resource requests that match real usage.
Pick the Right GPU Pricing Model
Compare on-demand, reserved capacity, committed use discounts, spot or preemptible options and independent GPU clouds. Aggregators often list multi-GPU instances at higher hourly rates, while independent providers may offer lower per-GPU prices depending on commitment, region and SLA. Validate apples-to-apples totals that include storage, data egress and support. Confirm availability targets, preemption policies and contract terms before you commit.
Migrate AI Workloads to IaaS with AceCloud
This On-prem to Cloud IaaS Guide will help you move confidently and execute IaaS Migration Steps. With AceCloud’s expert guidance, you can standardize the move from discovery to cutover with GPU-first infrastructure, managed Kubernetes and networking.
We will help you align outcomes, performance benchmarks and pilot safely, then scale waves at pace without surprises. Not just that, we will assist you in optimizing training and inference with GPU pricing models, observability and FinOps guardrails.
Our dedicated Cloud team is ready to assist with data transfer, landing zone design and zero-downtime migration patterns, ensuring you stay on budget and maintain availability. Start your free trial with AceCloud today or book a free consultation to roadmap your first migration wave.
Frequently Asked Questions:
Migrate AI workloads to IaaS by moving compute, storage, networking and MLOps from on-prem to a provider’s infrastructure. You keep control of VMs, GPUs and Kubernetes, while the provider handles hardware lifecycle, capacity and data center operations.
Begin with outcomes, benchmarks and inventory. Define KPIs and SLOs, capture current performance and cost, then catalog services, datasets, dependencies and security constraints. Appoint a migration architect, group workloads into waves and choose rehost, replatform or refactor by risk and value.
Use rehost for speed with minimal change. Pick replatform for quick gains like managed databases or containerized inference. Choose refactor when you need cloud-native scale, reliability and developer velocity, and your teams can absorb higher change.
Apply FinOps tagging, budgets and anomaly alerts. Monitor GPU utilization, throughput and egress. Rightsize instances, use mixed precision, tune autoscaling and compare on-demand, reserved, spot and independent GPU clouds. Providers like AceCloud offer GPU-first pricing and a 99.99%* SLA to balance cost and reliability.
Start with a site-to-site VPN for pilots. Move to private links like AWS Direct Connect or Azure ExpressRoute when you need steadier latency, higher throughput and predictable costs in production. Baseline latency, plan failover and include these choices in your landing zone design.

Related Post










Get in Touch

Credits First!
- 24*7 Human Support
- Pay-as-you-go Pricing
- No Egress Cost
- Multi Tier Security