
AI has pushed visualization forward real-time rendering, ray tracing, and interactive sims but those wins depend on a GPU that can keep frames smooth and color-accurate. Visual lag, stuttering, frame drops, reduced color fidelity, and other experience-related issues can be largely minimized by opting for a GPU capable enough to handle demanding visualization workloads.
The NVIDIA RTX 6000 Ada Generation, the successor to the RTX A6000, is NVIDIA’s flagship Ada Lovelace-based workstation GPU, designed for professional visualization, rendering and AI workloads.
The NVIDIA RTX 6000 Ada Generation features third-generation RT Cores, fourth-generation Tensor Cores, and next-gen CUDA cores with 48GB of graphics memory (vRAM), delivering massive improvements in performance when it comes to ray-tracing and remote rendering. In this blog, we explore the key features and benchmark performance of NVIDIA RTX 6000 Ada Generation from a remote rendering perspective.
What is Remote Rendering
Remote rendering offloads heavy scenes to a GPU server and streams frames or lightweight scene updates to the client. It frees the local machine for other tasks.
Though a local GPU can accelerate parallel workloads, heavily loaded desktops or laptops may struggle to multitask when the same GPU must handle rendering, encoding, and interactive applications simultaneously. Remote rendering can be handy in such scenarios, as all the compute-intensive rendering work is offloaded to the cloud GPU servers. With this, the critical resources of the host machine are now available for performing other tasks!
In most deployments, the server either streams rendered frames (pixel streaming) or sends lightweight scene/command updates that the client renders locally, depending on latency, bandwidth, and client GPU capabilities. Remote rendering definitely reduces the host (or client) hardware requirements, but its efficiency depends on network performance, server-side GPU throughput, and end-to-end encoding/decoding efficiency (e.g., NVENC/NVDEC and the streaming protocol).
As server-side GPU throughput is an integral aspect of remote rendering, a powerful GPU like the NVIDIA RTX 6000 Ada Generation can help in boosting the server-side throughput. The power of the latest CUDA cores and RT Cores in NVIDIA RTX 6000 Ada Generation can drive real-time design and enable faster and more efficient remote rendering.
Enabling High-Performance Visualization Workloads via Remote Rendering
Today’s professional workflows like 3D modeling, CAD simulations, complex scientific rendering, etc. require unprecedented performance for rendering, AI, graphics, and compute workloads.
The quality of visualization workloads such as awe-inspiring 3D visuals depends on a slew of factors that affects its performance, quality, and interactivity when rendering data or 3D content. Here are some of the key factors that have an impact on the quality and performance of the visualization workloads:
| Impacting Factor | Description |
|---|---|
| Dataset size and complexity | – Number of data points, resolution and variables in the dataset of the 3D model – Larger datasets understandably require more memory and processing for realizing effective rendering |
| GPU or hardware capabilities | – GPU architecture, core count, tensor/RT cores, CUDA cores, graphics memory, etc. – More powerful the GPU and its capabilities, better its performance for remote rendering |
| Rendering techniques | Algorithms like ray tracing, rasterization,etc. used for remote renderingAdvanced encoding/decoding, GPU hardware capabilities |
| Number of samples | – Samples per pixel determine the image accuracy. – More the number of samples, lesser is the noise but higher is the rendering time |
| Network latency | – Latency between the client and server during remote rendering |
| Parallelization and software optimization | How well the GPU and other hardware resources are leveraged by the visualization software“Using NVIDIA RTX 6000 Ada Generation with NVIDIA Omniverse enables collaborative, real-time rendering pipelines for complex design and simulation workflows. |
As GPU(s) are an integral part of the high-performance visualization through remote rendering, it is essential to opt for GPUs that can help in realizing that requirement. Akin to cloud computing, enterprises are preferring opex-based cloud compute over capex-heavy local workstation procurement for catering to requirements related to rendering, streaming workloads, and AI.
This is where the NVIDIA RTX 6000 Ada Generation sets a new benchmark, as it offers the performance and scalability needed to bring complex visual workloads to life remotely.
Deep Dive Into NVIDIA RTX 6000 Ada Generation
The NVIDIA RTX 6000 Ada Generation is built on the Ada Lovelace GPU architecture. It is a dual slot, full height, PCIe 4.0 workstation GPU with four DisplayPort 1.4a connectors.
It is a powerful workstation graphics card that excels at remote rendering, Generative AI, 3D modeling, video content & streaming, data visualization & simulation, amongst others. The Ada Lovelace microarchitecture is the foundation for the RTX 6000 Ada generation. Its predecessor RTX A6000 was based on the Ampere architecture!

Here are some of the architectural features in the NVIDIA RTX 6000 Ada Generation that largely benefit remote rendering and visualization workloads:
- 142 third-gen RT Cores for ray tracing (delivering 211 TFLOPs)
- 568 fourth-gen Tensor Cores for AI compute (delivering 1,457 TFLOPs)
- 18,176 next-gen CUDA cores for general purpose operations, with 91 TFLOPs of single precision performance
- Large 48 GB GDDR6 (with ECC) memory pool for unprecedented rendering, AI, graphics, and compute performance
- Memory Bandwidth: 960 GB/s
- Max. Power Consumption: 300W
- Graphics Bus: PCI-E 4.0 x16
- Four DisplayPort 1.4a connectors
This marks a major upgrade over the NVIDIA RTX A6000, which offers roughly 76 RT TFLOPS, about 310 Tensor TFLOPS and around 39 FP32 TFLOPS of single-precision compute.
Major Features of NVIDIA RTX 6000 Ada Generation
Now that we’ve had a look at the high-level features of the NVIDIA RTX 6000 Ada Generation, let’s look at the most important ones in more detail:
Ada Lovelace Architecture-Based CUDA Cores
According to NVIDIA’s specifications, the Ada-based RTX 6000 can deliver up to ~2× higher FP32 throughput than its Ampere predecessor in ideal conditions.
Graphics and simulation workloads on the desktop, including complex 3D computer-aided design (CAD) and computer-aided engineering (CAE) can benefit significantly from Ada Lovelace architecture.
Fourth-Generation Tensor Cores
The fourth-generation Tensor Cores add support for FP8 and improved sparsity, enabling up to ~2× higher AI throughput versus RTX A6000 for many training and inference workloads.
It also accelerates rapid model training and inferencing on RTX-powered AI workstations, helping developers iterate faster and deploy AI models more efficiently.
Third-Generation RT Cores
The third-generation RT Cores in the Ada architecture delivers 2x ray-tracing performance over the previous generation.
Along with speeding up remote rendering and complex visualization workloads, it also helps accelerate other workloads like photorealistic rendering of movie content, virtual prototyping of product designs, among others. Over and above, it also accelerates the rendering of ray-traced motion blur with higher visual accuracy.
AV1 Encoders
Though the eighth-generation dedicated hardware encoder (NVENC) with AV1 encoding has a major impact on streaming and broadcast, it also enhances workflows related to remote rendering and visualization.
It typically delivers up to ~40% better compression efficiency than H.264 at equivalent quality, enabling higher-resolution streaming of rendered visuals at similar bitrates. Visual fidelity improves without a significant increase in bandwidth demands.
NVIDIA RTX Virtual Workstation (vWS)
NVIDIA’s virtual workstation offering – vWS, also referred to as vGPU software stack, delivers workstation-class GPU resources virtually/remotely to users. NVIDIA RTX 6000 Ada Generation supports NVIDIA RTX Virtual Workstation (vWS) software, thereby allowing a personal workstation to be repurposed into multiple high-performance virtual workstation instances.
With RTX vWS/vGPU profiles, a single RTX 6000 Ada can be partitioned into multiple virtual GPUs (e.g., profiles tuned for CAD, M&E, or AI workloads). This lets IT teams trade off per-user performance vs. user density while still leveraging NVENC/NVDEC and RTX features in each virtual workstation.
Lastly, the 48GB GDDR6 memory in RTX 6000 gives its users large enough memory needed to work with large datasets and workloads such as rendering, data science, and simulation.
Why RTX 6000 Ada Generation Excels in Remote Rendering
In the earlier sections, we have already discussed some of the factors like network latency, virtualization and vGPU configuration, rendering application optimization, etc. that could impact the performance of tasks related to remote rendering.
Capabilities like Ada Lovelace architecture, third-gen RT Cores, massive 48 GB GDDR6 memory, fourth-gen Tensor Cores, etc. directly address the challenges associated with high-fidelity delivery, AI-based denoising & upscaling, and low-latency visuals at scale for multi-user cloud deployments.

Figure 1: NVIDIA RTX 6000 Specification
Accelerated Delivery of High-Fidelity Frames
Delivering high-fidelity frames, particularly in remote rendering, cloud visualization, or virtual workstation scenarios, becomes essential for ensuring visual accuracy and seamless user experience across distributed workstations. A lot also depends on the codec optimization, client-side decoding, and other factors to realize timely delivery of high-fidelity frames.
The optimized AV1 stack in NVIDIA’s Ada Lovelace architecture enables faster and more complex scene rendering, video transcoding, streaming, video conferencing, and vision AI workloads. With support for the AV1 video format and 2x more decoders & encoders, the RTX 6000 Ada Generation can host up to 3x more concurrent video streams than the previous generation. These factors help with smoother frame delivery and reduced latency in cloud-based visualization and rendering pipelines.
Third-generation RT Cores deliver up to 2x the ray-tracing performance over the previous generation. Third-generation RT cores provide higher effective RT TFLOPS for traversal and intersections. Shader Execution Reordering (SER) technology when combined with the powerful RT cores dynamically reorder inefficient workloads, improving shader performance and accelerating E2E ray-traced image rendering performance.
For remote rendering, all of this reduces the per-sample cost of path-tracing and translation into more accurate and visually stunning frames with minimal impact on latency.
The large 48 GB GDDR6memory is useful for letting the GPU handle extremely complex and data-intensive scenes. Visualizations, simulations, and designs that require massive amounts of graphical data can benefit significantly from this large frame buffer.
Support for AI-based Denoising and Upscaling
The Fourth-Generation Tensor Cores in the Ada architecture are purpose-built to accelerate frequently-used AI operations like matrix multiplications. The cores can elevate transformative AI technologies like intelligent chatbots, generative AI, NLP, computer vision, and NVIDIA Deep Learning Super Sampling 3.0 (DLSS 3).
The structured sparsity in Ada Tensor Cores makes the inference process faster and support for FP8 precision helps in reducing the memory footprint when compared to larger precisions like FP16, FP32, etc. This enables real-time AI-based denoising and upscaling, reducing visual noise and reconstructing higher-resolution frames efficiently.
Deep Learning Super Sampling 3.0 (DLSS 3) with rayreconstruction helps deliver superior real-time graphics performance. The all-new Optical Flow Accelerator (OFA) boosts rendering performance, delivers higher FPS, and significantly improves latency.

Figure 2: DLSS in RTX 6000 Ada Generation [Image Source]
The overall GPU workload is also reduced, as DLSS renders frames at a lower internal resolution and leverages AI to upscale them to a higher resolution.
Multi-user Cloud Deployment at Scale
The support for vWS software allows a single GPU to be partitioned into multiple virtual GPUs. Compatibility with the NVIDIA Omniverse platform enables multi-user collaboration and improved performance for real-time rendering at 4K with NVIDIA DLSS 3.

Figure 3: vGPU in RTX 6000 Ada Generation [Image Source]
A GPU Cloud platform like AceCloud integrates vGPUs powered by the NVIDIA RTX 6000 Ada architecture, whereby multiple users can access graphics-intensive virtual desktops and visualization applications simultaneously.
RTX 6000 Ada instances can be launched in minutes with no queue (or lock-in) via AceCloud’s self-service cloud console.
Minimized Network and Encoding Overhead with NVENC
The presence of NVENC, the dedicated hardware video encoder, helps in efficiently compressing the rendered frames for streaming. This minimizes the network bandwidth required for delivery of the high-quality frames to the host device (or machine).
For AR/VR streaming, the NVIDIA RTX 6000 Ada Generation can be paired with the NVIDIA CloudXR Suite. The combination of the RTX GPU, CloudXRSuite, and vWS enable XR applications to stream high-fidelity XR to Android and iOS devices over performant networks.
The dynamic adjustment to the network conditions lets CloudXR maximize the image quality and frame rates while minimizing the stuttering and effective latency.
Remote Visualization Workflow With NVIDIA RTX 6000 Ada
Now that we have covered the nuances of the RTX Ada GPU, let’s look at the overall remote rendering or visualization workflow in more detail. Shown below is a high-level of how a visualization workflow is handled with remote rendering handled by the RTX 6000 Ada workstation:
Encoding (Server side)
NVENC on the server-side of the RTX 6000 Ada Generation takes the rendered frames that are mostly raw images in the GPU memory. In order to minimize latency, the NVENC compresses/encodes the frames into a video stream in real-time with the AV1 encoder.
This drastically reduces bandwidth requirements and makes it feasible to stream high-fidelity frames over a network. The NVEC is 40 percent more efficient than H.264 codec, owing to which 1080p resolution content can be increased to 1440p quality while running at the same bit rate and quality.

Figure 3: Visualization Workflow [Image generated using AI]
Interactive Loop
All the GPU-intensive tasks and visualization workloads are offloaded to the NVIDIA RTX 6000 Ada hosted in a data center or cloud like AceCloud. Whenever any user interaction like editing in CAD design, etc. happens on the client/host machine; the corresponding request is sent to the remote GPU server.
Next, the GPU on the cloud re-renders the frame or makes the necessary changes inline with the user’s request. Once the changes are done, the NVENC encoder encodes the frame(s) and the encoded stream is sent back to the client machine. Finally, the frames are decoded on the client machine and rendered on the display.
Decoding (Client side)
As discussed in the earlier point, the encoded stream is received by the host machine. It uses the NVDEC (NVIDIA Decoder) if it has an NVIDIA GPU or some other software decoder for decoding the compressed frames.
The frame(s) are then displayed on the host’s screen in real time, synchronized with the display refresh rate.
Benchmarking: RTX Ada 6000 Generation vs. RTX A6000
The comparison of RTX Ada 6000 Generation with its predecessor i.e., NVIDIA RTX A6000 is inevitable, as both GPUs stack up impressively against each other in performance and capability. In this section, we explore the benchmark comparisons across rendering and virtualization workloads for both the GPUs.
The Ada Lovelace architecture in the RTX A6000 Ada helps in achieving close to double the rendering speed when compared to the RTX A6000 (based on the Ampere architecture). In a benchmark using Redshift, the RTX 6000 Ada completes a render in 87 seconds versus the RTX A6000’s 159 seconds.
This represents close to 83 percent speed-up, highlighting the rendering performance gains delivered by the Ada Lovelace architecture in Redshift workloads.
For Blender Rendering (i.e., the process of generating animations from 3D scenes created in Blender), the RTX 6000 Ada Generation achieves close to 117 percent higher score in comparison to the RTX A6000.
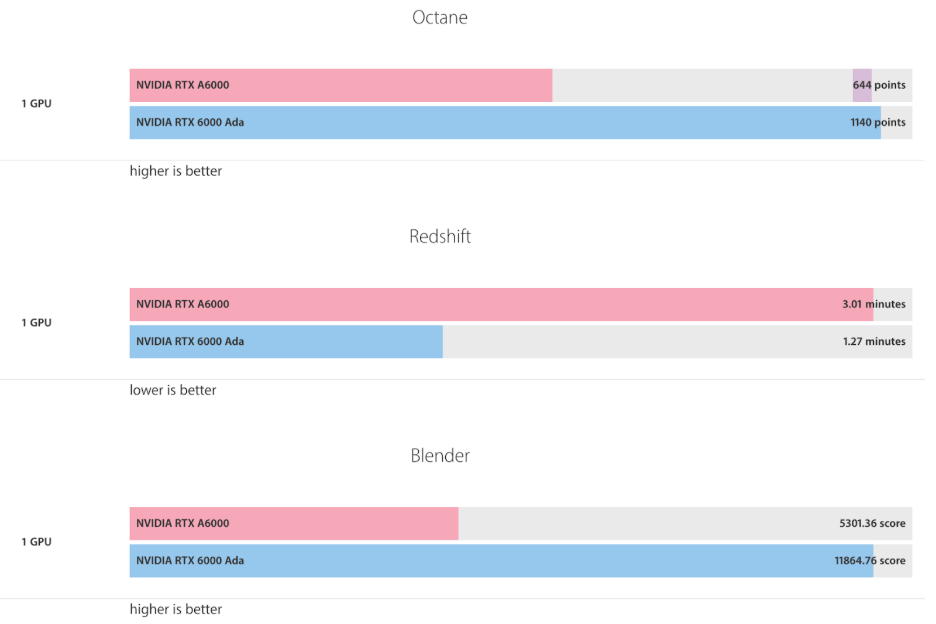
Figure 4: Benchmarks – Redshift, Blender, and Octane [Image Source]
The OctaneBench GPU benchmark is a performance test designed to measure how well a GPU performs in OctaneRender. In the Octane benchmark tests, the RTX 6000 Ada Generation scores 1140 whereas RTX A6000 scores close to 644.
The 1.77x performance impact equates to rendering gains owing to the Ada Lovelace architecture of the RTX 6000 Ada GPU. This also highlights the capability of the RTX 6000 Ada in delivering faster ray-traced rendering in Octane Render.

Figure 5: V-Ray Benchmarking Test [Image Source]
When it comes to GPU rendering, RTX 6000 Ada scores nearly double the performance of RTX A6000 in the benchmark tests. The RTX 6000 Ada performs exceptionally well even in multi-GPU configurations, with up to three in a workstation.
All the above benchmarks indicate that RTX 6000 Ada Generation GPUs out-performs its predecessor by a huge margin across rendering, AI, and virtualization workloads!
Primary Use Cases of RTX Ada 6000 Generation
Features like 48 GB of ECC memory, third-generation Gen RT Cores, 4th Gen Tensor Cores, etc. make RTX 600 Ada ideal for applications related to generative-AI, deep learning, 3D rendering, amongst others.
Here are some of the major use cases that can be catered with the NVIDIA RTX 6000 Ada Generation:
High-Fidelity 3D Rendering & Visualization
Real-Time Ray Tracing is significantly faster with the RTX 6000 Ada due to the presence of third-generation RT Cores in the Ada architecture. Due to this, the RTX 600 Ada is ideal for design evaluations for high-quality content rendering, virtual prototyping, and more.
Also, 48 GB GDDR6 ECC memory can handle large and complex 3D datasets without any memory overflows.
Deep Learning and Generative AI
RTX 6000 Ada can deliver up to 1.5x higher inference performance over the previous generation.
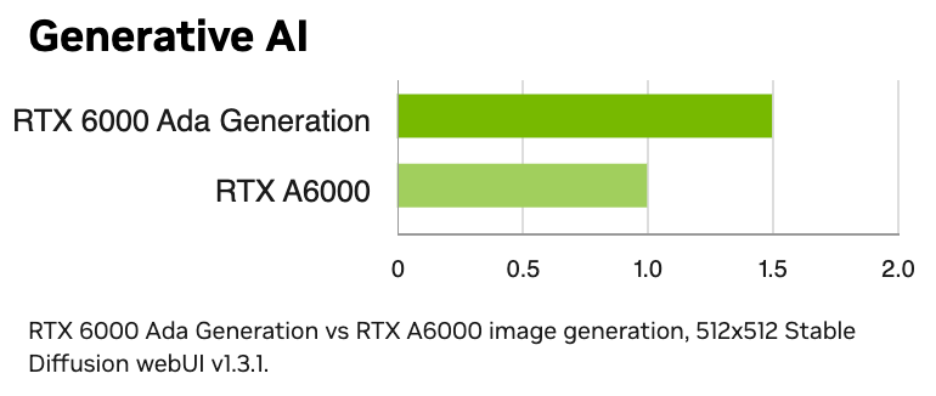
Figure 4: RTX 6000 Ada Generation performance with Generative-AI [Image Source]
As a result, RTX 6000 Ada offers substantial per-GPU performance gains for training and fine-tuning large vision models and mid-scale LLMs, and for high-throughput inference when properly batched.
Engineering Simulation (CAE/CFD)
The combination of high CUDA core count and 48 GB of ECC memory helps accelerate large meshes and transient simulations, while Tensor Cores can assist ML-augmented solvers and surrogate models.
Also, the RTX 6000 Ada can provide improvements for complex 3D CAD and CAE workloads, often speeding up the build and validation steps.
Virtual Production & Extended Reality (XR)
vGPU and CloudXR allow a single physical card to host multiple high-performance virtual workstation instances. This is helpful for remote teams and for streaming simultaneous XR sessions.
Wrap-Up
NVIDIA RTX 6000 Ada Generation, built on the Ada Lovelace architecture, offers significant benefits through its 48 GB ECC memory, fourth-generation Tensor Cores, and third-generation RT Cores, among other advances. It also offers superior ray-tracing capabilities.
Apart from handling real-time rendering with unprecedented efficiency, it also enables seamless remote rendering and collaboration when deployed with NVIDIA RTX Virtual Workstation (vWS) software. In a nutshell, NVIDIA RTX 6000 Ada Generation marks a paradigm shift in how creative professionals approach visualization and remote rendering.
You can leverage the full potential of Ada Lovelace architecture, 48 GB ECC memory, etc. to run demanding CAD, AI and simulation workloads on demand by renting NVIDIA RTX 6000 Ada from AceCloud.










