Google shipped Gemini 3 Pro, its most advanced Gemini model so far. OpenAI rolled out GPT-5.1, a mid-cycle upgrade that powers the latest ChatGPT and Codex experiences. Both feel incredibly capable in day-to-day use, yet they are not the same type of engine.
This comparison looks at Gemini 3 Pro vs GPT-5.1 from a builder’s point of view:
- How they differ in architecture, context and multimodality
- How they behave for coding, RAG and agents
- Where each is stronger, and when a multi-model strategy makes more sense
At AceCloud, we see teams using both proprietary models via API, as well as open models running on our GPU cloud. The goal here is not to crown a winner, but to help you design a stack that fits real workloads.
Update (Dec 12, 2025): This post covers ChatGPT 5.1. If you’re evaluating the newest model, go to our Gemini 3 Pro vs ChatGPT 5.2 comparison (changes, benchmarks, pricing).
TL;DR – Which model wins where?
If you just need the short version:
- Gemini 3 Pro is ahead on multimodal and “deep thinking” tasks: large documents, screenshots, complex diagrams, and long-horizon reasoning. It offers a 1M-token context window and tops several reasoning benchmarks like Humanity’s Last Exam and ARC-AGI-2.
- ChatGPT 5.1 (GPT-5.1) is currently the best all-round coding and agentic model in OpenAI’s lineup, with a 400k combined context window and tight integration into ChatGPT, Codex tools, and partner ecosystems.
- For day-to-day chat and writing, most users find GPT-5.1 slightly more polished and “human” in tone, while Gemini 3 is stronger when you throw messy, multimodal inputs at it (screenshots, PDFs, multi-file repos).
Gemini 3 Pro vs ChatGPT 5.1: Quick Comparison
| Dimension | Gemini 3 Pro | ChatGPT 5.1 / GPT-5.1 |
|---|---|---|
| Positioning | Google’s flagship multimodal model for complex reasoning, “agentic” tasks & computer use. | OpenAI’s flagship GPT-5-series model optimized for coding, agents & general reasoning. |
| Context window (API) | 1M tokens in / 64k out | Up to ~400k combined (≈272k input / 128k output) in API variants. |
| Core modalities | Native text, images, audio, video, PDFs, and large code/repos. | Text + vision; audio/video via separate tools; strong tool & function calling. |
| Benchmarks (reasoning) | Leads on several reasoning benchmarks (e.g., Humanity’s Last Exam, ARC-AGI-2). | Very strong but slightly behind Gemini 3 Pro on some newest reasoning benchmarks. |
| Benchmarks (coding) | Strong coding and “agentic” claims, competitive on new coding tests. | GPT-5.1 + Codex variants are currently among the best coding/agent models. |
| API pricing (per 1M tokens)* | Input ≈ $2.00, output ≈ $12.00 via Google Cloud / partners. | Input ≈ $1.25, output ≈ $10.00, with cheap prompt caching. |
| Knowledge cutoff | Around early 2025 (varies by variant). | GPT-5.1 inherits GPT-5’s 2025 knowledge, updated with recent events through tools. |
| Access for end-users | Gemini app, Google Search “AI Pro/Ultra”, Workspace integrations. | ChatGPT web & mobile (Free/Plus/Pro/Business), Microsoft Copilot, partner platforms. |
| Best fit | Long-context multimodal tasks, UI understanding, deep reasoning. | Coding agents, chat UX, and general purpose assistants integrated into existing tools. |
In Plain terms:
- Gemini 3 Pro is your long-context multimodal engine.
- GPT-5.1 is your tool-heavy, agent-first workhorse.

Model overview: Gemini 3 Pro vs GPT-5.1
Gemini 3 Pro:
Gemini 3 Pro is Google’s newest flagship model in the Gemini family. It is:
- A 1M-token context model (1M input, 64k output)
- Natively multimodal across text, images, audio, video, PDFs and full code repositories
- Available via the Gemini API, Vertex AI and inside consumer products like the Gemini app and Google Search
Google positions it as its most advanced reasoning and coding model, with better multimodal understanding and more robust safety compared with Gemini 2.5.
JetBrains reports more than a 50 percent improvement in solved coding benchmark tasks versus Gemini 2.5 Pro when running Gemini 3 Pro inside their IDE experiments.
ChatGPT-5.1:
GPT-5.1 is OpenAI’s latest frontier model in the GPT-5 series. It is:
- A 400k-context reasoning model (272k input, 128k output) in Azure and partner documentation
- Integrated into ChatGPT, Microsoft Copilot and exposed via the OpenAI API
- Priced at $1.25 / 1M input tokens, $10 / 1M output tokens, $0.125 / 1M cached input tokens
Under the hood GPT-5.1 has two modes, Instant and Thinking, and uses adaptive reasoning. It spends more compute on hard problems and responds faster to straightforward prompts.
OpenAI markets GPT-5.1 as its best model for coding and agentic tasks across industries.
Benchmarks: who’s ahead on reasoning, multimodality & coding?
Benchmarks are not the whole story, but they do give useful signals.
Reasoning & “hard exam” benchmarks
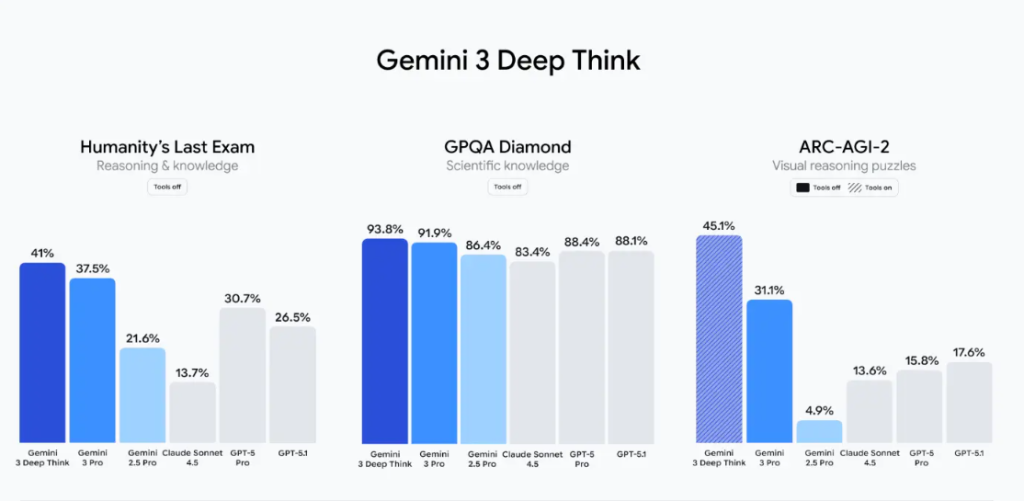
Several public and partner reports show Gemini 3 Pro leading on “hard exam” style tests:
- On Humanity’s Last Exam, Google and third-party analyses put Gemini 3 Pro around the high-30% range, compared with mid-20s for GPT-5.1.
- On ARC-AGI-2, a visual and abstract reasoning benchmark, Gemini 3 Pro also posts top scores among frontier models.
This lines up with anecdotal experience: Gemini 3 Pro often shines when questions require multi-step reasoning, pattern recognition, and mixing text with images or diagrams.
Multimodal & perception benchmarks
On multimodal tests (vision + language, mixed media, exams with images):
- Gemini 3 Pro leads on several multimodal math/vision datasets, such as MMMU-Pro and MathArena Apex, suggesting strong perception and symbolic reasoning.
- GPT-5.1 is very capable with images and charts, but most recent stacks put it slightly behind Gemini 3 on the newest, hardest multimodal leaderboards.
Coding & agent benchmarks
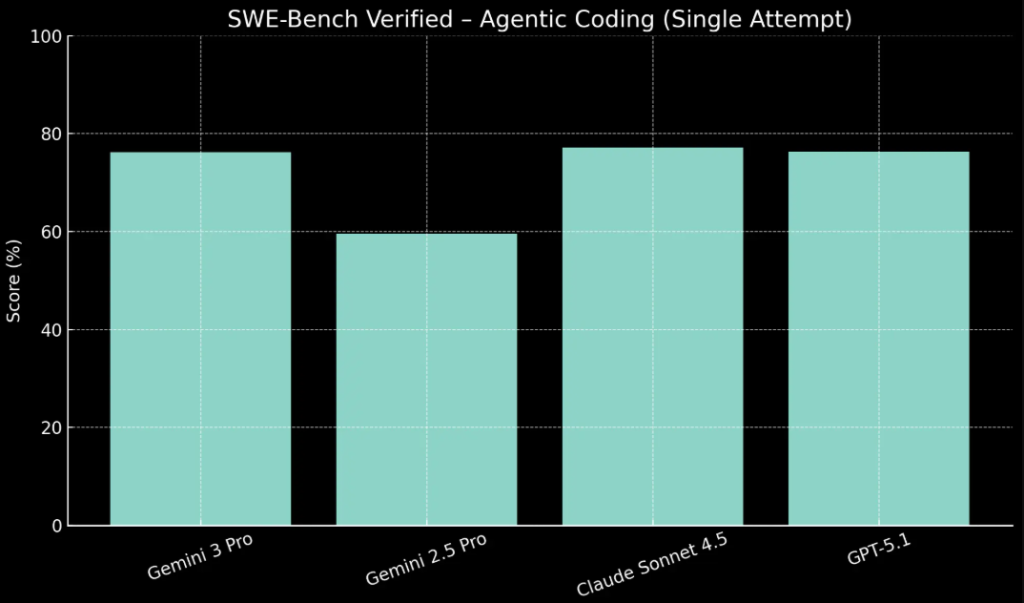
When we shift from pure reasoning to coding and agents, GPT-5.1 closes the gap – and often leads:
- OpenAI’s own data and external evaluations show GPT-5.1 and GPT-5.1-Codex handling long-horizon coding tasks with fewer retries, particularly when combined with their CLI and IDE tools.
- Gemini 3 Pro performs very well on code generation benchmarks, but its biggest advantage is still context length + multimodal code understanding (e.g., repos plus screenshots plus logs).
Benchmarks summary
| Dimension | Better Default Today | Why it matters in practice |
|---|---|---|
| Pure reasoning (HLE, ARC-AGI-2) | Gemini 3 Pro | Stronger on very hard, long-form reasoning tasks. |
| Multimodal tests (MMMU, screenshots, math diagrams) | Gemini 3 Pro | Better at integrating images + text + long context. |
| Coding benchmarks / agents | GPT-5.1 / Codex | More mature coding tools and ecosystem. |
| Cost-adjusted quality | Depends on task | GPT-5.1 slightly cheaper; Gemini 3 may reduce retries on hard multimodal tasks. |
Real-world scenarios: how they behave on actual tasks
Rather than just graphs, let’s look at three everyday scenarios and what you can realistically expect from each model. These are based on public benchmarks plus typical behavior we’ve seen in production workloads.
1. Everyday productivity, writing & analysis
Example tasks
- Turn a messy email thread + attachments into next-step action items.
- Draft a blog or LinkedIn post from a short outline.
- Explain a scientific concept at “10-year-old” and “PhD” levels.
What Gemini 3 Pro tends to do well
- Handles mixed inputs (screenshots + PDFs + bullet points) in a single prompt, and keeps more of the original context because of its 1M window.
- Good at connecting dots across long threads or documents without heavy retrieval engineering.
What GPT-5.1 tends to do well
- Very polished writing style; often shorter, clearer outputs with fewer tweaks needed.
- Strong “instruction adherence”: if you say “use bullet points, 2-sentence paragraphs, friendly but professional tone”, it usually follows that reliably.
Verdict: For pure writing & chat, slight edge to GPT-5.1. For long, messy, multimodal inputs, Gemini 3 Pro is often more forgiving.
2. Coding a small production-grade feature
Example task
“Build a small REST service that ingests log files, stores them in a database, and exposes an endpoint to query recent errors. Use TypeScript, write tests, and include a Dockerfile.”
Gemini 3 Pro behavior (typical)
- Comfortable reading longer specs or existing codebases in one go, thanks to the large context window.
- Good at understanding screenshots of error messages, architecture diagrams, or API docs directly.
GPT-5.1 behavior (typical)
- Very strong at iterative coding: propose structure, adjust after tests fail, and apply small patches.
- Plays extremely well with agentic tools (e.g., a CLI that runs tests, a repo browser, or code-edit tools) – especially with Codex-style APIs.
Verdict: For production-style coding agents, GPT-5.1 usually wins today. For massive, multimodal code + docs contexts, Gemini 3 can be the better “code + context” analyst.
3. RAG & knowledge assistants (policies, wikis, PDFs)
Example task
- A compliance copilot that answers questions from policy PDFs, internal wiki pages, and email archives.
- You send a query like: “For a customer in Germany, can we store telemetry data outside the EU, and what exceptions exist?”
What really matters
- Grounding (answer sticks to the provided docs).
- Relevance & completeness (no missing clauses).
- Conciseness (short, clear answers with citations).
Gemini 3 Pro strengths
- Able to ingest more raw context per query (entire policy bundles, longer meeting transcripts).
- Often better at integrating tables, images, and complex formatting directly, reducing the amount of pre-processing you need.
GPT-5.1 strengths
- Very good at structured outputs, JSON answers, and tool calls (e.g., “search again”, “fetch this chunk”) – great for multi-step RAG pipelines.
- Strong at summarizing and condensing long-chains of retrieved snippets into a clean answer.
Verdict: For simple RAG over standard text, both work well; GPT-5.1 might win on tooling. For “everything in one huge prompt” multimodal RAG, Gemini 3 Pro has a real advantage.
Pricing & context windows: what you actually pay
Pricing moves quickly, but as of late 2025:
API pricing (high level)
- Gemini 3 Pro (via Google, Vertex AI, or aggregators):
- Input tokens: around $2.00 per 1M.
- Output tokens: around $12.00 per 1M.
- GPT-5.1 (via OpenAI & partners):
- Input tokens: $1.25 per 1M.
- Output tokens: $10.00 per 1M.
- Prompt caching can reduce repeated input cost by ~90%.
Simple example: 200k-token analysis job
Imagine you:
- Send 200k input tokens (multiple docs)
- Get back 5k tokens of output (a detailed report)
Approximate cost:
- GPT-5.1
- Input: 0.2 × $1.25 ≈ $0.25
- Output: 0.005 × $10 ≈ $0.05
- Total ≈ $0.30
- Gemini 3 Pro
- Input: 0.2 × $2.00 ≈ $0.40
- Output: 0.005 × $12 ≈ $0.06
- Total ≈ $0.46
So for this workload, Gemini 3 is ~50% more expensive per call – but may save you extra calls if its larger context and multimodal strengths let you do everything in one shot.
Where the 1M-token context really matters
- If you regularly exceed 300–400k tokens per query even after chunking and RAG optimization, Gemini 3’s 1M context can be a hard requirement.
- For most production apps, you can stay under 200k tokens per request with a good retrieval layer – in which case GPT-5.1’s cost advantage is meaningful.
Everyday users: which should you pick?
For non-developers and knowledge workers, the choice is simpler.
Choose Gemini 3 if…
- You already live inside Google Workspace (Docs, Sheets, Slides, Gmail).
- You care a lot about AI that can read, summarize, and reason over big PDFs, presentations, and screenshots in one go.
- You’re using Google’s AI Pro/Ultra tiers or Gemini app, and you want a “native” experience.
Choose ChatGPT 5.1 if…
- You want the most polished general assistant for day-to-day writing, brainstorming, and coding.
- You rely on the ChatGPT ecosystem – custom GPTs, GPT Store, agent mode, integrations with third-party tools, or Microsoft Copilot.
- Your company is already invested in OpenAI-based workflows and security reviews.
In practice, most power users end up with both (e.g., Gemini for documents + ChatGPT for code and chat).
Developers & infra teams: which stack when?
Here’s a more opinionated mapping for teams building on cloud GPUs and managed LLM infra.
If you’re building…
- Coding agents, CI/CD copilots, or dev tools
- Default: GPT-5.1 (and associated Codex models).
- Also consider Gemini 3 when:
- You need to feed entire repos, architecture diagrams, and logs into one context.
- You’re building “watch the screen and act” style agents using Google’s computer-use stack.
- Enterprise RAG assistants (policies, wikis, support)
- Default: Multi-model:
- GPT-5.1 for tool-heavy pipelines (search, retrieval, fact checking).
- Gemini 3 for multimodal & giant-context queries.
- Use routing: pick a model based on query length, modality, and sensitivity. This approach suits AI workflow automation software, enabling models to manage documents, knowledge retrieval, support and complex workflows with accuracy and scalability.
- Default: Multi-model:
- Analytics, research & BI copilots
- If your data lives in BigQuery / Google Cloud, Gemini 3 integrates cleanly with Google’s ecosystem.
- If your stack is Azure / OpenAI-first, GPT-5.1 may be easier to plug into existing services.
- Customer-facing chatbots & product assistants
- Choose based on where your users already are:
- Products tightly integrated with Google identity → Gemini 3 feels native.
- Products already exposed via ChatGPT plugins or Copilot → GPT-5.1.
- Choose based on where your users already are:
Multi-model in practice: running Gemini 3 and GPT-5.1 together on AceCloud
You don’t have to “marry” one model. A realistic 2025 stack:
- Routing layer
- Detect: query length, modality (text vs text+image), required latency, and sensitivity.
- Route heavy multimodal/long-context requests to Gemini 3 Pro.
- Route coding/tool-heavy tasks to GPT-5.1.
- Shared retrieval & feature store
- Unified vector + keyword search index feeding both models.
- Model-agnostic features (embeddings, metadata) so you can swap models as prices/quality change.
- Guardrails & observability
- Central logging, evals, red-teaming, and cost dashboards across both models.
- Continuous offline evaluation on your own test sets (RAG accuracy, coding correctness, etc.).
- GPU and infra strategy
- Use managed endpoints for Gemini 3 and GPT-5.1 where compliance demands it.
- Run open-source companion models (e.g., for cheap reranking or lightweight tasks) on AceCloud GPUs to reduce spend and latency.
This multi-model approach usually beats “one model everywhere” on cost, reliability, and performance.
Final thoughts
For AI/ML enthusiasts and builders the real question is not “Is Gemini 3 better than GPT-5.1” but:
Which model fits this specific task, in this stack, under this budget.
- Choose Gemini 3 Pro when you care about 1M-token long context, rich multimodal inputs and deep visual reasoning, especially inside Google Cloud and Workspace.
- Choose GPT-5.1 when you care about agents, tools, coding workflows and cost-efficient 400k-context calls that run well across many environments.
Frequently Asked Questions:
No single model “wins” everywhere. Gemini 3 Pro leads on multimodal and deep reasoning benchmarks, while GPT-5.1 is generally better for coding, tools, and everyday chat. The best choice depends on your workload and ecosystem.
For most coding agents, IDE integrations, and CI/CD automation, GPT-5.1 (plus Codex variants) is currently the better default due to its mature tools and ecosystem. Gemini 3 is competitive and particularly useful when you need to analyze very large, multimodal repos or logs in a single pass.
Both models can power strong RAG systems. GPT-5.1 tends to shine in tool-driven pipelines and structured queries, while Gemini 3 Pro is excellent for long, multimodal contexts where you want to stuff more raw content into the prompt. Many teams route between them based on query length and modality.
Yes – and you probably should. A multi-model router that can call Gemini 3 or GPT-5.1 depending on the request usually outperforms any single-model setup on both quality and cost.
- For end-users, access to Gemini 3 is often included in Google’s premium AI tiers (AI Pro/Ultra, Workspace add-ons).
- ChatGPT has a free tier plus paid Plus/Pro/Business plans, with GPT-5.1 available on paid tiers and via API.
For production workloads, both models are billed by tokens, and costs depend heavily on how you architect prompts and retrieval.