Anthropic describes Claude Opus 4.7 as the most capable model for complex reasoning and agentic coding. 1M token context window, 128k max output tokens, and adaptive thinking.
Claude Opus 4.7 has landed exactly at the right moment. In 2026, the AI conversation has moved past novelty and into execution. Teams want Large Language Models that can code, reason across long contexts, interpret visuals, use tools, and stay reliable in production. That is why this release is getting so much attention. Anthropic launched Claude Opus 4.7 on April 16, 2026, calling it its most capable generally available model, with major gains in advanced software engineering, instruction following, long-running tasks, and high-resolution vision.
What makes the launch feel bigger than a routine model update is the broader ecosystem around it. Claude Opus 4.7 is available across Claude products and the Claude API. Anthropic says it is also available through Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. GitHub began rolling it out to Copilot Pro+, Business, and Enterprise users on launch day, which immediately put the model in front of working developers rather than just early testers.
What is Claude Opus 4.7?
Claude Opus 4.7 sits at the top of Anthropic’s generally available lineup. Anthropic describes it as the most capable generally available model for complex reasoning and agentic coding, with a 1M token context window, 128k max output tokens, and adaptive thinking.
Pricing stays at $5 per million input tokens and $25 per million output tokens, matching Opus 4.6 rather than introducing a premium frontier tier.
This model is built for teams whose work does not fit neatly into short prompts and short answers. Anthropic recommends it for long-horizon agentic work, knowledge work, vision tasks, and memory-heavy tasks. That makes it especially relevant for developers, product teams, analysts, legal and finance workflows, AI startups, research teams, and enterprise operations groups that need Large Language Models to work across files, tools, documents, and long project threads.
Why is Claude Opus 4.7 Trending?
Claude Opus 4.7 arrived as the market shifted from chatbot experiments to agentic systems that can get the work done. Anthropic’s positioning reflects that change. It describes Opus 4.7 as built for complex reasoning and agentic coding, while its Managed Agents platform now gives developers a secure environment where Claude can read files, browse the web, run commands, and execute code. That pairing makes the release feel like part of a larger platform move, not just a benchmark play.
Why developers, founders, and enterprises are paying attention to Claude Opus 4.7?
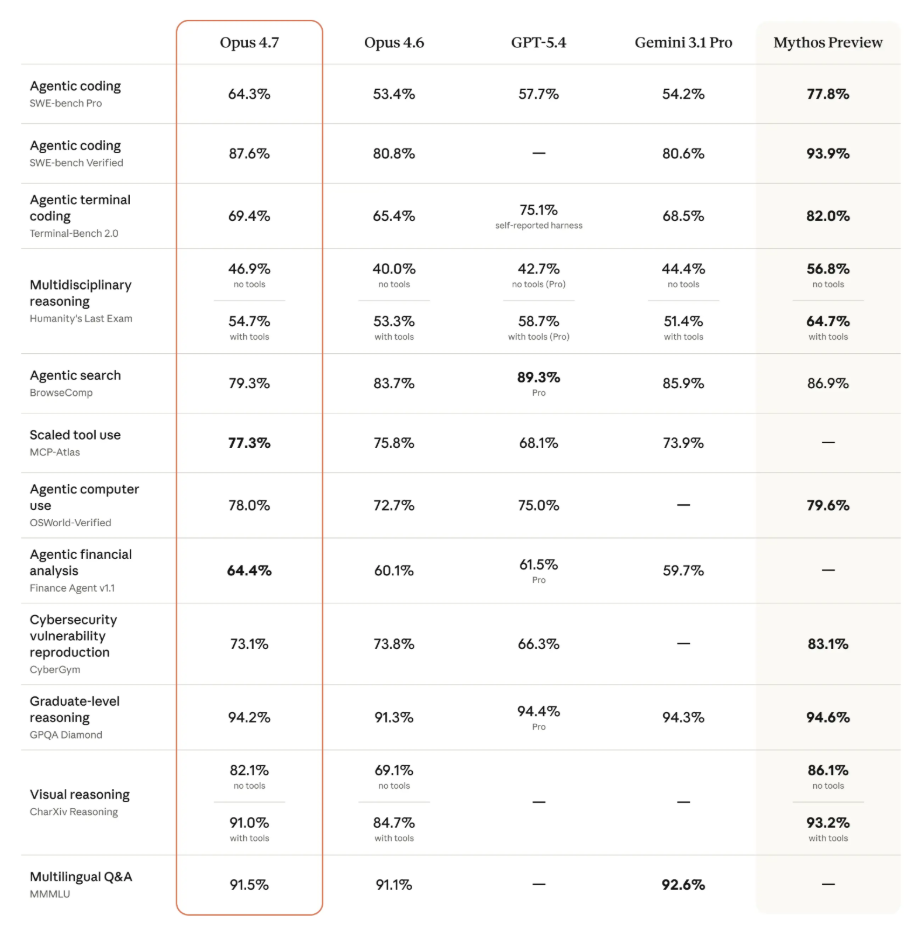
The core appeal is practical. Claude Opus 4.7 is a notable improvement over Opus 4.6 on advanced software engineering, especially on the hardest tasks, and says users can hand off difficult coding work with more confidence.
GitHub’s early testing showed stronger multi-step task performance, more reliable agentic execution, and better long-horizon reasoning in tool-dependent workflows. Microsoft framed the model as a direct upgrade path for enterprise teams already building inside Foundry.
What does this release say about the future of Large Language Models?
The deeper signal is that Large Language Models in 2026 are being judged less on clever chat output and more on operational usefulness. Anthropic highlights gains in memory, professional work, visual understanding, and long-running task execution. That points to a future where the leading models act more like AI work engines than chat interfaces.
What’s New in Claude Opus 4.7?
Here’s what Anthropic is offering with the new Claude Opus 4.7:
1. Stronger agentic coding and software engineering performance
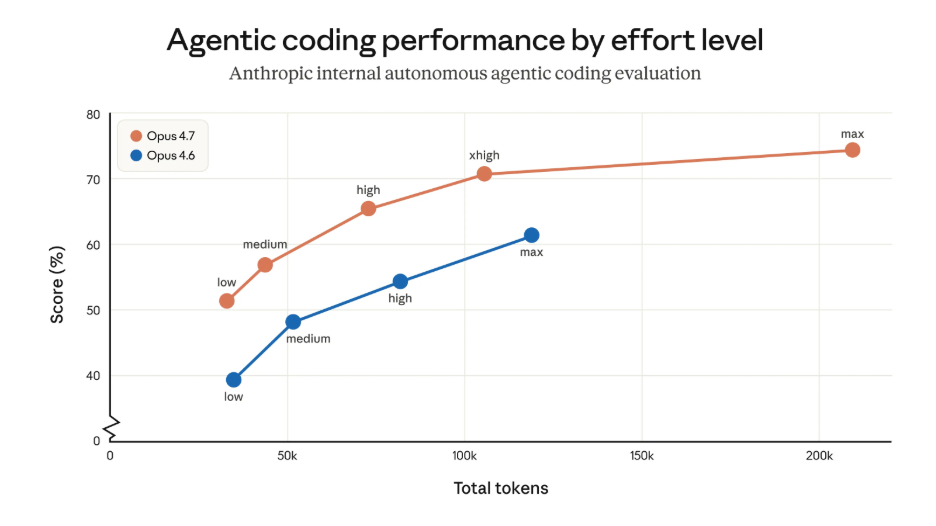
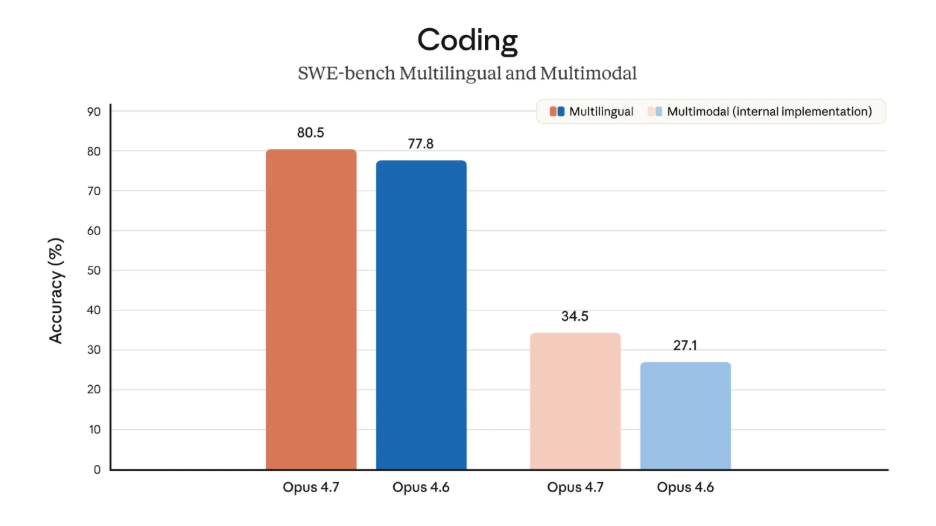
The most headline-worthy improvement is coding. Opus 4.7 improved resolution by 13 percent over Opus 4.6 on its 93-task coding benchmark, including four tasks that neither Opus 4.6 nor Sonnet 4.6 could solve. The model is better at verifying its own outputs before reporting back, which is exactly the kind of change that matters in real engineering work.
2. Better multimodal understanding
Opus 4.7 is Anthropic’s first Claude model with high-resolution image support. The maximum image resolution increased to 2576 pixels on the long edge, up from 1568 pixels on prior models, which Anthropic says improves performance on computer use, screenshots, artifacts, and document understanding. The company also notes that coordinate mapping is now 1:1 with actual pixels, which simplifies image-grounded workflows.
3. More reliable instruction following
Anthropic’s migration guide makes a point that prompt engineers should not miss. Claude Opus 4.7 is more literal than Opus 4.6, especially at lower effort levels. It is less likely to infer requests that were never stated, which improves predictability for APIs, structured extraction, and production pipelines. That may sound subtle, but for teams building on Large Language Models, instruction fidelity is often the difference between a useful agent and an expensive guesser.
4. Long-context and long-running workflow improvements
Claude Opus 4.7 handles complex, long-running tasks with more rigor and consistency, and it supports the same 1M token context window as Opus 4.6 without a long-context premium. Anthropic says the model is better at file system-based memory, remembering important notes across long, multi-session work. In plain terms, it is built to stay useful after the first answer.
5. New effort controls and task budgets
One of the most practical upgrades is not flashy at all. Anthropic added a new xhigh effort level and recommends it as the starting point for coding and agentic use cases. It also introduced task budgets in beta, which give the model an advisory token allowance across the full agentic loop, including thinking, tool calls, tool results, and final output. That helps teams manage cost and quality more deliberately instead of just hoping the model stays efficient.
Claude Opus 4.7 vs Earlier Claude Models: Which is Better?
Is Claude Opus 4.7 better than the 4.6 version? Well, that still requires considerable benchmarking. But this is what we found while writing this post:
Claude Opus 4.7 vs Claude Opus 4.6
The jump from 4.6 to 4.7 is meaningful because Anthropic did not just add a feature or two. It upgraded the model’s coding performance, vision capabilities, memory, and workflow reliability while keeping pricing flat.
Anthropic explicitly frames it as a step-change jump in agentic coding rather than a small incremental tune-up.
That said, early community reaction has not been uniformly positive.
In a widely discussed Reddit thread, many users described Opus 4.7 as a regression from 4.6 in everyday use. Common complaints included weaker adherence to personal preferences, fabricated claims about having performed searches, more filler-heavy responses, and a tendency to stop short on tasks that 4.6 would push through.
A smaller group in the same discussion noted that 4.7 still showed value on certain difficult coding and debugging workflows, so the feedback is critical, but not completely one-sided. Since this is anecdotal user feedback rather than a controlled benchmark, it is best treated as a real signal, not a final verdict.
Improvements for day-to-day users
For day-to-day users, the improvements are easier to understand in workflow terms. You get better performance on multi-step coding tasks, more useful visual reasoning, stronger output quality on slides and docs, and a model that gives more regular progress updates during long agentic traces. GitHub also points to stronger tool-dependent workflow performance, which is exactly where many developer users feel the difference first.
Where teams may need to adjust prompts or workflows
This upgrade is not frictionless. Opus 4.7 uses a new tokenizer that may consume up to about 35 percent more tokens for the same text, and non-default sampling values for parameters like temperature, top_p, and top_k can return errors. Manual extended thinking budgets are no longer supported on Opus 4.7, and teams need to move to adaptive thinking with effort controls instead.
Why this Matters for Large Language Models in 2026?
Claude Opus 4.7 is trending because it fits the broader transition happening across Large Language Models. Businesses are no longer buying into AI just to generate text faster. They want systems that can run a workflow, inspect evidence, use tools, preserve context, and finish a task with fewer hand-holds. Anthropic’s Managed Agents offering reinforces that exact shift.
Why multimodal AI and tool use now matter more than raw text generation
The best production systems in 2026 are increasingly model-plus-tools systems. Anthropic’s platform now supports managed agents, structured outputs, prompt caching, and tool-driven workflows around Opus 4.7. Add the new high-resolution image support and you get a model that can work across screenshots, charts, office files, and agent loops rather than just produce polished prose.
How Claude Opus 4.7 fits into the AI agent race
Anthropic also connects Opus 4.7 to the next stage of the agent race. The model includes stronger cyber safeguards as it tests guardrails that could inform broader release paths for Mythos-class systems. That makes Opus 4.7 important not only as a productivity model, but also as a sign of how vendors are trying to make more capable Large Language Models deployable at scale without losing control.
How to Use Claude Opus 4.7 in 2026?
Let’s check out the several use cases of Claude Opus 4.7, especially with its improved offerings over Opus 4.6.
Best use cases for developers
Developers should look first at refactoring, debugging, code review, repo analysis, terminal workflows, and long-running agentic coding.
Anthropic’s own data and GitHub’s early testing both suggest that Opus 4.7 shines when tasks stretch across multiple steps, tools, and verification cycles.
Best use cases for businesses
For businesses, the sweet spot is research, document analysis, finance work, workflow automation, and operations tasks that mix reasoning with evidence.

Anthropic says Opus 4.7 is state-of-the-art on GDPval-AA, a third-party benchmark for economically valuable knowledge work, and says internal testing showed stronger finance analysis, more professional presentations, and tighter task integration.
Best use cases for content and knowledge teams
Content, strategy, and knowledge teams can benefit from the model’s stronger document work, slide quality, visual comprehension, and memory across long sessions.
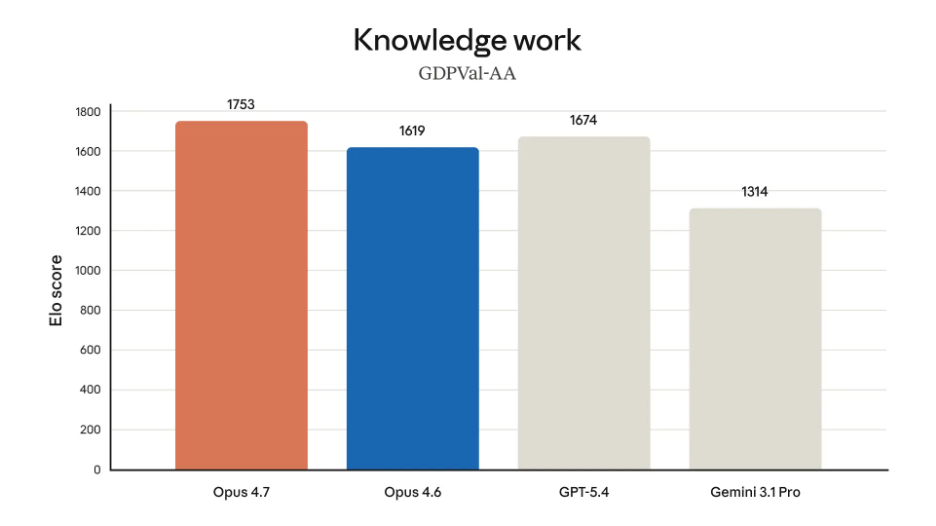
This is especially useful for research synthesis, briefing creation, expert reports, and multimodal review workflows that depend on more than raw text generation.
When Claude Opus 4.7 is the right choice and when it is not
Claude Opus 4.7 is the right choice when the cost of being wrong is high and the task is complex enough to justify deeper reasoning. It is less compelling for lightweight summarization, simple extraction, or latency-sensitive routine flows where a cheaper and faster model can do the job. Anthropic points to careful model routing rather than using Opus for everything.
Tips for Generate Better Results with Claude Opus 4.7
Here are some of the practical tips you can use to make the most of Claude Opus 4.7:
Write prompts with clearer deliverables
Because Opus 4.7 follows instructions more literally, vague prompts leave more value on the table. Clear deliverables, boundaries, and validation criteria matter more here than with a looser model. Anthropic explicitly says teams should review and retune prompts after migration.
Use tools, memory, and structured workflows
The best results come when the model is part of a system. Managed Agents, structured outputs, secure tool use, and memory-aware workflows let Opus 4.7 act instead of merely suggest. That is where modern Large Language Models compound their value.
Balance quality, speed, and cost
Use high or xhigh effort where reasoning depth matters, and start with at least 64k max_tokens for xhigh or max workloads. Use task budgets when you need the model to self-moderate across an agentic loop, and downsample images when full fidelity is unnecessary to control token spend.
Challenges and Things to Watch Before Switching
However, you should be wary of these challenges while making the switch:
API and workflow changes teams should not ignore
Teams upgrading from earlier Claude models need to account for real breaking changes. Remove non-default sampling parameters, replace manual thinking budgets with adaptive thinking, update the model name, and explicitly opt in if the UI depends on summarized visible thinking. Such adjustments can break production flows.
Cost and token considerations
Pricing did not go up, but token behavior did change. The new tokenizer may increase token counts by up to about 35 percent on the same fixed text, and high-resolution images can use up to roughly three times more image tokens than prior models. That means cost discipline still matters, even when the price sheet looks unchanged.
Better performance still needs humans
Even a stronger model still needs review loops. Anthropic highlights more direct tone, more literal interpretation, fewer tool calls by default, and fewer subagents spawned unless prompted otherwise. Those are manageable behaviors, but they reinforce a familiar truth in 2026. Better Large Language Models reduce supervision. They do not eliminate the need for it.
Is Claude Opus 4.7 Worth the Hype?
Yes, in several areas. Claude Opus 4.7 looks like a real step forward in agentic coding, multimodal reasoning, long-session usefulness, and enterprise-ready workflow execution. The fact that Anthropic held pricing steady while raising capability makes the release more significant than a standard frontier refresh.
At the same time, no single model fixes weak architecture, poor prompts, bad retrieval, or missing governance. Opus 4.7 still requires prompt tuning, token budgeting, and careful migration. Teams that treat it like a magic swap-in upgrade will miss part of its value and may even create new cost or reliability problems.
Train Your LLM Models with AceCloud
Claude Opus 4.7 is trending because it captures the direction of AI in 2026 better than most releases do. This is not just a story about one more model launch. It is a story about Large Language Models becoming more useful as work systems. Better coding, stronger vision, longer context, tighter instruction following, and more mature agent infrastructure all point in the same direction.
Build, fine-tune, and scale your LLMs on AceCloud’s powerful cloud infrastructure. From GPU-ready environments to expert guidance, AceCloud helps accelerate AI innovation with confidence. Book a free consultation to discuss your goals, optimize performance, and connect with our cloud experts for a tailored path to production success in 2026 today.
Frequently Asked Questions
Claude Opus 4.7 is Anthropic’s most capable generally available model as of April 16, 2026. It is designed for complex reasoning, agentic coding, long-context work, and multimodal tasks.
It is trending because it arrived as teams are moving from basic chat use cases to AI agents that can code, use tools, interpret visuals, and complete longer workflows. Anthropic also launched it with broad platform availability, which increased visibility across developer and enterprise audiences.
Anthropic highlights stronger agentic coding, better instruction following, improved long-running task execution, higher-resolution image support, a new high effort level, and task budgets in beta. Pricing remains the same as Opus 4.6.
Yes. Claude Opus 4.7 supports a 1M token context window and up to 128k max output tokens, which makes it useful for large codebases, long documents, multi-file analysis, and memory-heavy workflows.
It is best suited for developers, product teams, analysts, researchers, and enterprises that need Large Language Models for complex reasoning, coding, document analysis, visual understanding, and long-horizon agent workflows. Anthropic positions it especially well for agentic coding and knowledge work.
Yes. Claude Opus 4.7 works with the same platform tools and features as Opus 4.6, and Anthropic’s Managed Agents offering provides infrastructure for file access, command execution, web browsing, and secure code execution.
Yes. Anthropic’s migration guide notes several important changes, including removal of manual extended thinking budgets, errors for non-default sampling values in some settings, and behavior changes tied to stricter instruction following. Teams should re-test prompts and workflows before upgrading production traffic.
For high-value use cases, yes. Claude Opus 4.7 is aimed at production-grade workflows where better reasoning, stronger coding performance, and multimodal understanding create measurable value. It is less necessary for lightweight tasks where a lower-cost model can already perform well.