
The NVIDIA H200 GPU is a data center accelerator designed for production generative AI, where real-world bottlenecks are often memory capacity, memory bandwidth and tail latency (p95) rather than peak TFLOPS.
As LLMs move into customer-facing workflows, longer contexts, larger KV caches and higher concurrency can increase memory pressure and expose data-movement limits.
According to McKinsey report, 88% of respondents report regular AI use in at least one business function, yet about one-third say they have begun scaling their AI programs.
- NVIDIA H200 GPU architecture: Hopper Tensor Cores paired with software paths designed for transformer workloads (e.g., Transformer Engine) to improve efficiency with lower-precision execution where accuracy targets allow.
- NVIDIA H200 specifications (memory-first): 141GB HBM3e with 4.8TB/s memory bandwidth—positioned by NVIDIA as nearly double H100 memory capacity with 1.4× more bandwidth.
- Scale-up and sharing features:
- NVLink up to 900GB/s plus MIG partitioning up to 7 instances, listed as 18GB each on H200 SXM and 16.5GB each on H200 NVL.
- Real-world applications: Long-context LLM inference with larger KV caches, RAG and embedding pipelines under concurrency, multi-GPU training and memory-bound HPC workflows where data movement not peak TFLOPS limits throughput.
- Vendor-reported performance signals: NVIDIA highlights up to 1.9× faster Llama2 70B inference and 1.6× faster GPT-3 175B inference versus H100, with results dependent on configuration.
Key Architecture Features of NVIDIA H200
The NVIDIA H200 prioritizes the memory subsystem and serving responsiveness, memory-bound AI and HPC pipelines improve even when peak TFLOPS is not the limiting factor.

Built on the NVIDIA Hopper architecture, H200 pairs transformer-optimized compute with next-gen HBM3e memory to improve throughput consistency and reduce stalls in memory-bound pipelines.
1. Enhanced AI inference
AI inference is the stage where trained models generate outputs such as classifications, predictions and content. In real deployments, inference performance is less about peak compute and more about throughput under concurrency, stable p95 latency and cost per token.

Image Source: NVIDIA
NVIDIA positions H200 as an inference accelerator built to deliver high throughput at lower total cost of ownership when deployed at scale. On NVIDIA’s H200 page, the company highlights performance examples versus H100, including:
- 1.9× faster Llama2 70B inference
- 1.6× faster GPT-3 175B inference
2. Reduceenergy and total cost of ownership (TCO)
Rather than claiming a fixed percentage improvement, it is more accurate to frame H200’s efficiency the way NVIDIA does: better energy efficiency and lower total cost of ownership, driven by higher performance, especially for memory-bound AI and HPC workloads.
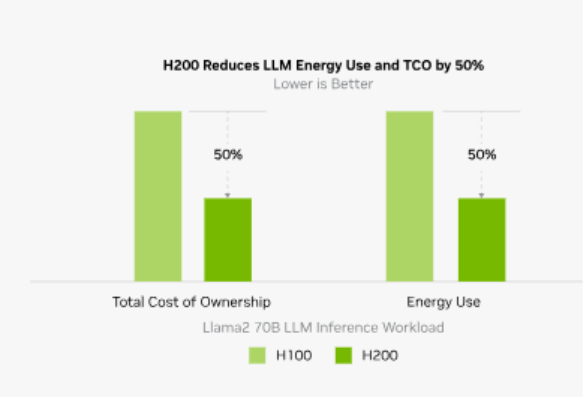
Image Source: NVIDIA
NVIDIA also states that H200 delivers this within the same power profile as the H100. In practice, that means for many workloads you can achieve:
- higher throughput at similar power envelopes
- fewer GPUs needed to hit an SLA in some cases, which lowers rack, networking and operational overhead
3. Multi-Instance GPU
Multi-Instance GPU, also called MIG, improves utilization by partitioning a single GPU into isolated instances, each with dedicated slices of compute and memory. This is especially useful for:
- multi-tenant inference platforms
- mixed workloads such as production inference, staging and experimentation
- Kubernetes-style scheduling where you want predictable resource isolation
On H200, NVIDIA lists:
- up to 7 MIGs at 18GB each on H200 SXM
- up to 7 MIGs at 16.5GB each on H200 NVL
4. Memory boost
The defining upgrade in H200 is its memory subsystem. NVIDIA specifies:
- 141GB HBM3e
- 4.8 TB per second memory bandwidth
NVIDIA describes this as nearly double the H100’s capacity with 1.4× more memory bandwidth. That claim aligns with the published H100 SXM specs:
- H100 SXM: 80GB
- H100 SXM bandwidth: 3.35 TB per second
5. Multi-precision computing
H200 supports a wide range of data types that help balance accuracy and speed across workloads. NVIDIA’s official H200 specs list performance lines for FP8, BF16, FP16, INT8, TF32, FP32 and FP64, reflecting broad support for mixed-precision training and inference.
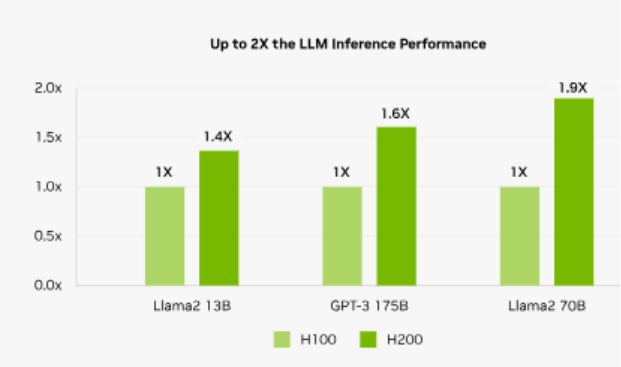
Image Source: NVIDIA
In practice:
- FP8, BF16 and FP16 are commonly used to speed up transformer training and inference while keeping accuracy within targets
- INT8 often appears in optimized inference paths
- FP32 and FP64 remain relevant for certain numerically sensitive operations and HPC workloads
- NVLink for scale-up performance
Large models often require multiple GPUs. NVLink is the high-speed GPU interconnect that improves scale-up communication inside a node, which matters for tensor parallelism, pipeline parallelism and distributed inference. H200 supports NVLink up to 900 GB per second, helping reduce communication bottlenecks when workloads span multiple GPUs.
Recommended Read: High-Performance Computing with Cloud GPUs for AI/ML – All You Need to Know
H200 SXM vs H200 NVL: Which One Fits Your Deployment?
H200 is commonly discussed in two main variants, and the best choice depends on how you deploy AI infrastructure.
H200 SXM
It is typically used in integrated platforms designed for maximum density and performance. It supports higher power envelopes up to 700W, which can be important for sustained performance in purpose-built systems.
H200 NVL
It is a PCIe form factor designed to fit broader enterprise server environments. It supports power up to 600W and is often aligned with air-cooled rack deployments.
Practical decision rule
- Choose SXM when you are building high-density training nodes.
- Choose NVL when you need easier integration into existing data center footprints or cloud-style server fleets.
What are the Real-world Applications and Use Cases?
NVIDIA H200 maps well to workloads where memory bandwidth, capacity and latency shape real outcomes. These use cases matter because production systems slow down when data movement stalls compute or when tail latency breaks user-facing SLAs.
AI and ML training and inference
Training time can drop when more model state stays in fast memory and stalls between layers are reduced. Inference consistency can also improve by supporting larger KV caches and higher concurrency, which helps teams deploy large models faster.
Retrieval augmented generation and embeddings at concurrency
RAG stacks add embedding generation, retrieval, reranking and generation. Under real traffic, these stages can become bandwidth heavy and memory bound. H200’s higher HBM capacity and bandwidth can help keep working sets on GPU and reduce latency spikes during concurrent requests.
Agents and long-context serving
Agentic systems and long-context applications increase KV cache size and amplify memory pressure. When memory becomes the bottleneck, tokens per second drops and p95 latency climbs. H200 is built to reduce those stalls and stabilize throughput.
Rendering and VFX
Rendering and 3D modeling workflows can run faster when large scenes and complex assets fit well within GPU memory and parallel processing paths. Shorter iteration cycles allow more frequent design testing, less waiting between revisions and faster delivery of final outputs.
Professional visualization
Rendering and 3D modeling workflows can run faster when large scenes and complex assets fit well within GPU memory and parallel processing paths. Shorter iteration cycles allow more frequent design testing, less waiting between revisions, and faster delivery of final outputs.
Healthcare and genomics
Genomics pipelines, medical imaging, and research simulations often rely on large datasets and repeated compute steps. Faster AI-driven analysis can shorten time-to-insight, helping teams move from detection to decision with fewer delays in critical workflows.
Financial services
High-frequency trading, pricing models, and risk analysis depend on low latency and robust parallel computation. Reduced processing delays can improve reaction time to market changes, while parallelism supports evaluating more scenarios within fixed decision windows.
Automotive and autonomous vehicles
Sensor data processing and real-time simulation require consistent latency and high throughput. These capabilities can speed up validation of perception and planning stacks, strengthen safety analysis, and support more efficient development of autonomous systems.
Launch Your NVIDIA H200 GPU Workloads on AceCloud
Production GenAI rewards teams that solve bandwidth, capacity and latency bottlenecks early. The NVIDIA H200 GPU delivers 141GB HBM3e and 4.8TB/s bandwidth to keep KV cache and activations on fast memory, stabilize p95 latency and raise tokens per second.
If you are planning H200 adoption, the fastest path is to validate with your own model, context length and concurrency profile. AceCloud gives you access to H200 cloud instances plus enterprise networking, predictable billing and migration support so you can move from pilot to production without capex delays.
Start with a short proof of performance this week. Book a consultation to size your cluster, run a benchmark and get a tailored quote.
Frequently Asked Question:
H200 is used for enterprise gen AI, LLM training and inference, HPC and data center acceleration where memory bandwidth and capacity drive results.
NVIDIA positions H200 with 141GB HBM3e and 4.8TB/s bandwidth, which it frames as nearly double H100 capacity and 1.4x bandwidth.
Yes, it is positioned for transformer-based training and inference, including large models that stress KV cache and memory movement.
Memory-bound inference, large-context serving, retrieval-heavy pipelines and HPC kernels that scale with bandwidth usually benefit the most.
Yes. AWS, Azure and Google Cloud have announced or launched H200-based instances, and specialized GPU cloud providers also offer H200 options.










