
Generative AI is playing a significant role across domains & industries spanning content creation, entertainment, healthcare, gaming, amongst others. The Generative AI landscape is evolving at a fast pace, with rapid advancements in Large Language Models (LLMs) that are foundational to tasks associated with processing using Natural Language.
The global LLM market size, which was estimated at USD 5,617.4 million in 2024, is projected to grow at a CAGR of 36.9 percent from 2025 to 2030. Techniques such as Transfer Learning and Supervised Learning are also playing a key role in leveraging pre-trained knowledge for adapting to new tasks more effectively.

Figure 1: LLM Market Size [Image Source]
Running Large Language Models require significant computational power for training as well as inference. This is where technological enhancements in hardware, primarily GPUs (Graphics Processing Units) and TPUs (Tensor Processing Units) have led to acceleration in training & inference processes, leading to efficient handling of more complex AI models.
LLMs, be it open-source or proprietary (closed source), are redefining industry expectations as they enable startups & enterprises to harness the potential of AI for their business needs. Depending on the model’s licensing and characteristics, LLMs can be fine-tuned, distilled, and deployed across a range of platforms. As both open-source and proprietary LLMs have their own share of advantages & shortcomings, we look into the key differences between the LLMs, highlighting their advantages, challenges, and ideal use cases.
What are Large Language Models – A Primer
To start with, Large Language Models (or LLMs) are machine-learning models that are typically based on the transformer architectures. The underlying transformer in the LLM is a set of neural networks that comprises a decoder with self-attention capabilities.

Figure 1: Simplified view of LLM Architecture [Image Source]
LLMs are trained on huge sets of data (or text) using the semi-supervised or self-supervised learning techniques. LLMs are highly efficient in natural language processing, making them best-suited for tasks associated with natural language understanding and generation.
LLMs are widely used in diverse fields like code generation, copywriting, sentiment analysis, automated customer service, online search, amongst others. On a case-by-case basis, businesses have the flexibility to self-host or deploy LLMs (open-source or proprietary) on third-party secure and scalable cloud providers like Ace Cloud.
The choice between open-source and proprietary LLMs would depend on the licensing terms, intended tasks, model capabilities, long-term costs, and more. Let’s dig deeper into the open-source vs. proprietary divide in further sections of the blog!
Understanding Open-Source LLMs
Open-Source Large Language Models (LLMs) are built on the foundational principles of transparency, collaboration, and freedom to use (& modify) principles that are applicable to any form of open-source software (or framework). Open-source LLMs are AI models whose source-code, pre-trained weights, documentation, training datasets, etc. are available for use & modification in the public domain.
For example, an open-source LLM like DeepSeek AI surprised the AI world with its immense capabilities achieved at a fraction of cost in comparison to other open-source models. Open-source LLMs thrive with contributions from the community, not limited to developers, researchers, and organizations that foster AI diversity & collaboration.
These LLMs have played an integral role in accelerating the advancements in the field of NLP. Users can customize the respective open-source model by fine-tuning LLM for specific tasks (e.g., chatbots, translation, sentiment analysis, etc.). Also, open-source LLMs can be optimized to run on a variety of hardware, depending on the use case, model’s size, and its minimal computational requirements.
Salient Benefits Of Open Source LLMs
Open source LLMs offer a slew of benefits, the major ones are listed below:
Cost Effectiveness
Akin to open-source software, there are no upfront costs of using open-source LLMs. This makes an economical option for AI developers and businesses looking to salvage the benefits of LLMs for achieving their use cases.
Hugging Face, considered to be the largest provider of open-source LLM infrastructure, also provides open-source tools like LangChain and LlamaIndex majorly used for the development of applications using LLMs. Hugging Face lists a wide range of open-source and community-uploaded models (e.g., GPT, BERT, T5, etc.) that can be used for tasks like NLP, computer vision, and multi-modal tasks. A majority of these models can be further fine-tuned for achieving specific tasks.
Apart from AI hobbysists, and researchers; emerging startups & large enterprises like IBM, VMWare, Perplexity, Shopify, etc. use open-source LLMs for automating tasks, as well as, solving customer pain-points.
Customization and Fine-Tuning
Depending on open-source model’s licensing, design, and use case requirements, an appropriate open-source LLM can be fine-tuned and modified to suit the industry needs. For example, the Mistral 7B – a popular high-performing model with 7 billion parameters can be fine-tuned, modified, and deployed for use cases spanning code generation, summarization, and more.
On similar lines, GPT-J, a 6 billion open-source model can be fine-tuned for applications like summarization and content generation. There are many more open-source pre-trained models (e.g., LLaMA, GPT, BERT, BLOOM, Falcon, etc.) that can be fine-tuned and deployed as per the requirements of your AI application.
Improved Security And Privacy
Unlike open-source LLMs, proprietary LLMs often rely on cloud APIs (e.g., OpenAI’s GPT-4 on Azure), where data is processed on the provider’s servers. This leads to raising concerns related to data leaks (or retention), as noted in the Skyflow results (March 05, 2024).
On the other hand, users of open-source have to manage security policies, data security and retention on their own. As open-source models can be modified and redistributed, it is imperative to source the code from trusted repositories. Stars, forks, commit history, overall community usage, and maintainer(s) details are some of the factors that can be looked into when sourcing the code.
Encrypting data at rest with AES-256 encryption or using secure channels for data in motion are some of the security best-practices for ensuring data is securely encrypted both in transit and at rest. As security is of prime importance, a more practical approach is to deploy open-source LLMs on a secure and scalable public cloud infrastructure like Ace Cloud. With this approach, you leverage the extensibility and security aspects of the cloud provider’s managed infrastructure.
Minimal Third-Party Dependency
LLM code, weights, fine-tuning scripts & tools, and other related resources are freely available for use for open-source LLMs. There are no licensing fees, as most open-source LLMs are released under licenses such as MIT, Apache 2.0, or CC-BY. For example, all the repositories of the Mistral AI – developers of popular LLMs such as Mistral 7B, Mixtral 8x7B, etc. are free to use for research and commercial purposes.
With the open-source advantage, critical resources can now be allocated for fine-tuning & customizing LLMs as per the use case and optimizing it for improved security & performance. It is suggested to opt for the best-suited GPU(s) that can cater to your data processing needs. The NVIDIA H200 vs H100 vs A100 vs L40S vs L4 GPUs comparison guide can be your handy resource for choosing the ideal GPU.
Most Popular Open-Source LLMs
Companies like Brave, VMWare, Shopify, Intuit, Perplexity, etc. are leveraging the benefits offered by open-source LLMs for their business needs. Mistral Large 2, DeepSeek R1, LLaMA 3.3 70B, Qwen 2.5-72B-Instruct, and Gemma-2-9b-it are some of the open-source LLMs that are widely in use.
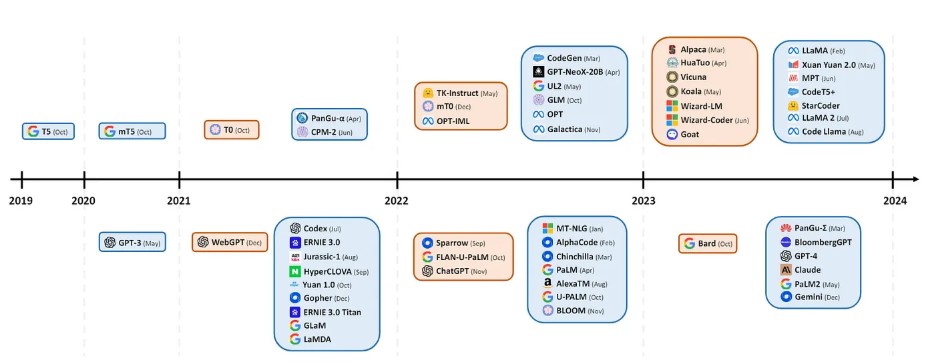
Figure 3 — Models on the upper half signify open-source availability, whereas those on the bottom half are closed-source [Image Source]
The choice of the LLM largely depends on factors like use case, model size, computing requirements, community support, inference speed, among others. In the interest of time, here are the top 5 open-source LLMs based on downloads & activity (pas per Hugging Face), community engagement, enterprise adoption, and more:
Llama (Meta AI)
Llama is a family of LLMs released by Meta AI starting in February 2023. At the time of writing this blog, Llama 4 is the latest version of the Llama LLM. Llama models come in different sizes, ranging from 1 billion to 2 trillion parameters. Llama also comes in smaller sizes that require less compute power namely – 7B, 13B, 33B, and 65B.
As stated in the official Llama GitHub repo, Llama 2 is a deprecated LLM model on some platforms and it is recommended to use newer models like LLaMA 3.2 and LLaMA 4 that offer better performance and support. Llama 4 (Scout and Maverick), as well as Llama 3.1 & 3.2 models, can be fine-tuned for research and some commercial purposes. The Llama Stack codifies best practices across the Llama ecosystem, further simplifying AI application development.
| Llama Repo | https://github.com/meta-llama |
| Llama Stack | https://github.com/meta-llama/llama-stack |
| Llama 4 (Hugging Face) | https://huggingface.co/docs/transformers/en/model_doc/llama4 |
| Llama 3 (Hugging Face) | https://huggingface.co/docs/transformers/en/model_doc/llama3 |
Mistral (Mistral AI)
Mistral-7B is the first large language model released by Mistral AI. Mistral-7B and Mistral-8x7B LLMs are both known for their efficiency and performance. The Mistral-8x7B is a high-quality sparse mixture of expert models (SMoE) with open weights.
Mixtral-8x7B-Instruct-v0.1 is the latest LLM with 8×7 billion parameters based on the (MoE) architecture. It is designed for high performance in natural language tasks.
Like other open-source LLMs, these models are also licensed under the Apache 2.0 license. The Pixtral-12B-2409 is a Multimodal model of 12 billion parameters and 400 million parameter vision encoder. This popular model has both text and image understanding capabilities.
Mistral-finetune, an official light-weight codebase based on LoRA, helps with memory-efficient and performant fine-tuning of Mistral models.
| Mistral AI Repo | https://github.com/mistralai |
| Mistral-finetune | https://github.com/mistralai/mistral-finetune |
| Mistral-7B (Hugging Face) | https://huggingface.co/mistralai/Mistral-7B-v0.3 |
| Mixtral-8x7B-Instruct-v0.1 (Hugging Face) | https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1 |
QWEN (Alibaba Cloud)
QWEN by Alibaba Cloud has released a slew of open-source models that have gained significant prominence in tasks related to Natural Language Processing (NLP). The Qwen2.5-Coder Series of LLMs is widely popular in assistive AI programming. As per a NextBigFuture report, by the Qwen2.5-Coder Series is regarded as the top open-source model for coding, topping HumanEval (~70–72%) and LiveCodeBench (70.7) benchmarks.
The Qwen2.5-72B (successor of Qwen2-72B) is a powerful and high-performing LLM comprising approximately 72.7 billion parameters. It is capable of handling a wide range of tasks in commercial and research domains.
Over and above, Qwen has multimodal variants, namely Qwen2.5-VL and Qwen2.5-Omni, that cater to text, audio, vision, and video applications. The addition of Qwen3 models introduces a hybrid approach to problem solving (i.e., thinking and non-thinking modes).
| Qwen Repo | https://github.com/QwenLM/Qwen |
| Qwen3 | https://qwenlm.github.io/blog/qwen3/ |
| Qwen2.5-72B (Hugging Face) | https://huggingface.co/Qwen/Qwen2.5-72B |
| Qwen2.5-Coder | https://github.com/QwenLM/Qwen2.5-Coder |
DeepSeek-R1 (DeepSeek)
DeepSeek-R1 from DeepSeek AI is a popular open-source LLM based on the MoE architecture. DeepSeek-R1 excels at tasks related to technical documentation, coding, logical reasoning, math, etc. outperforming popular proprietary models like OpenAI’s o1 and Anthropic’s Claude 3.5 Sonnet.
DeepSeek-R1-Distill models are fine-tuned open-source models that use the samples generated by DeepSeek-R1. The DeepSeek-R1 model has 671 billion parameters that it learns during training.
| DeepSeek-R1 Repo | https://github.com/deepseek-ai/DeepSeek-R1 |
| DeepSeek-R1 (Hugging Face) | https://huggingface.co/deepseek-ai/DeepSeek-R1 |
Gemma (Google)
As stated in the official documentation, Gemma is a collection of lightweight, state-of-the-art open models based on the technology that powers Google’s Gemini models. The model is available in different sizes like 2B, 7B, 9B, and 27B; thereby catering to different requirements.
At the time of writing this blog, Gemma 3 is the latest publicly available Gemma model, whereas Gemma 3n is available in the preview stage. Lage 128K context window, multilingual support in over 140 languages, and availability in different sizes makes Gemma 3 a great choice for tasks related to text generation, image understanding tasks, summarization, and reasoning.
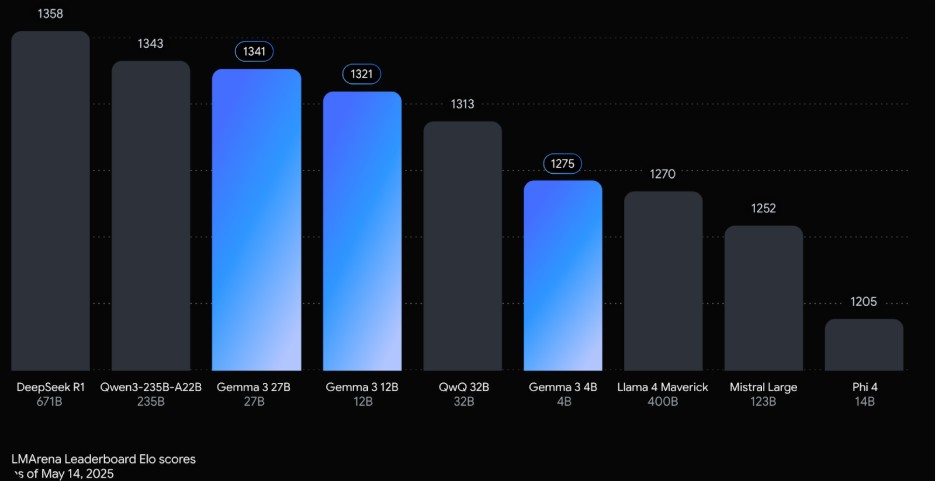
Figure 4: Gemma 3 – Performance & Benchmarks [Image Source]
The light-weight variant of Gemma 3 can also run on a single TPU or GPU. As seen from the above benchmarks, Gemma 3 outperforms many similarly-sized popular models when it comes to logical understanding and reasoning tasks.
| Gemma (Official) | https://deepmind.google/models/gemma/ |
| Gemma GitHub Repo | https://github.com/google-deepmind/gemma |
| Gemma-3-27b-it (Hugging Face) | https://huggingface.co/google/gemma-3-27b-it |
Apart from the open-source LLMs covered here, you could also into options like Phi-4, Falcon-H1, amongst others. The Open-Source LLM Leaderboard by Hugging Face is a good resource to keep an eye on the best-performing open-source LLMs.
With so many options in hand, it is recommended to look into factors like model performance, benchmarks, open-source license, ecosystem support, multimodal & multilingual support before zeroing on the best-suited open-source LLM!
Understanding Proprietary LLMs
Unlike open-source LLMs, proprietary (or closed-source) LLMs are advanced AI systems that are developed and maintained by organizations. Understandably, the nuances of the LLM (i.e., model weights, training data, fine-tuning procedure, etc.) are not available in the public domain.
In many cases, AI-engineering teams within an organization use a combination of general-purpose datasets and proprietary data for training the developed proprietary LLM. Architecture and weights are also kept closed-source by the respective organization. BloombergGPT, a closed-source LLM by the financial major Bloomberg, is trained on 50 billion parameters comprising a wide range of financial data.
Proprietary LLMs built for specialized domains or tasks backed by proprietary data and resources, are considered to be more accurate and performant when compared to fine-tuned open-source LLMs tasked to do the same job! Does this mean that open-source LLMs are less accurate? Well, the accuracy and performance of the LLM (both open-source and proprietary) largely depends on the quality, quantity, diversity, and relevance of the training data for that specific domain/task.
OpenAI’s GPT-4, Anthropic’s Claude, Google’s Bard, Cohere, Jurassic, and xAI Grok 3 are some of the popular proprietary large language models. Now, let’s look at areas where closed-source LLMs stand-out when compared to open-source models.
Salient Benefits Of Proprietary LLMs
Proprietary (or closed-source) LLMs offer a slew of benefits, the major ones are listed below:
Enterprise Support and Security
A proprietary LLM offers the developmental organization more fine-grained control over the data-security aspects of the model. Hence, more rigorous security measures can be taken by a dedicated team of LLM security engineers when it comes to monitoring and patching vulnerabilities in the model.
This by no means indicates that open-source LLMs are less secure, the benefit that closed-source LLMs brings is related to controlled access and proprietary oversight. Ultimately, the security of the LLM (whether open-source or closed-source) entirely depends on the short & long-term implementation, usage, and maintenance of the model.
Proprietary Advancements
Closed source LLMs cater to a specific domain (or a use case) and the model advancements are guarded by Intellectual Property (IP) rights. This could turn out to be a major differentiator for enterprise AI-applications that offer speed and performance benefits for enterprise tasks.
Bespoke AI tools for businesses in the field of finance, healthcare, etc. can serve as a significant advantage vis-à-vis its competition. As the closed-source models are continually trained and optimized with industry-specific proprietary data, they have a higher edge as far as solving industry-specific use cases is concerned.
Suited for on-premise deployment
If a business is planning for an on-premise LLM deployment; proprietary LLMs with enterprise-grade security and tailored configurations can be a preferred choice. Enhanced security and improved scalability helps in ensuring that the sensitive data is always kept in-house.
Most open-source LLMs, such as Llama, Mistral, and other models from Hugging Face can be hosted and run on services like Google GCP, AWS, Azure, amongst others. Though most of the popular open-source LLMs (e.g, Llama, Mistral AI, etc.) can also be deployed on-premise, closed-source providers have higher flexibility to streamline the process with professional services.
Over & above, proprietary (or closed-source) LLMs also offer benefits related to improved API documentation, regular model updates, amongst others. Though proprietary LLMs seem ideal for industry-specific use cases that are backed by proprietary data and continual optimization, it is not a zero-sum game! The nature of the model is just one aspect of the broader set of activities planned in the process of AI development.
Most Popular Proprietary (closed-source) LLMs
Like open-source LLMs, there are a number of options when it is about opting for the best-suited proprietary model. Software majors like Google, X, Meta, etc. offer closed-source models where the code and training data is kept under the wraps to stay ahead in the AI-race.
Here are the top picks for proprietary LLMs based on the LLM model trends as of 2025:
GPT-4.5 Orion (OpenAI)
GPT-4.5 is the largest model so far released by Open AI. The model, released in February 2025, is considered as a step forward in scaling up pre-training and post-training. This multimodal LLM outperforms its predecessors in tasks related to text, image processing, and reasoning. It is also much better in following the user intent, owing to which it excels at programming, writing, and solving other practical problems.
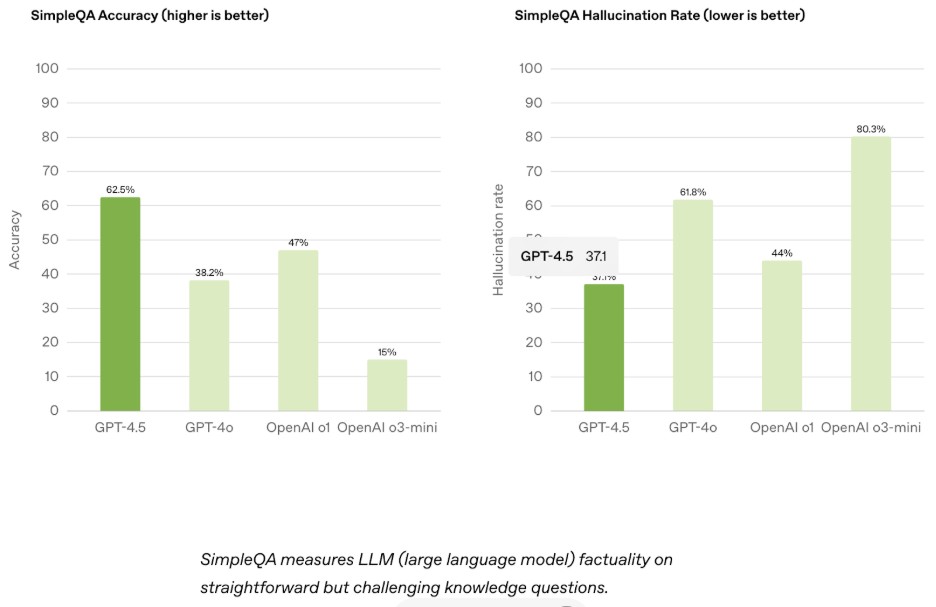
Figure 5 : GPT 4.5 benchmarks [Image Source]
GPT-4.5 supports 128K-token context window and is available as a research preview at $20/month. As stated in the GPT-4.5 launch documentation, the model is trained with new techniques for supervision that are combined with traditional supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) methods like those used for GPT‑4o.
Grok 3 (xAI)
Grok 3 is a 314-billion parameter LLM that was released in November 2023. It is developed and maintained by xAI. One of the catchy things about Grok is the humorous and unconventional manner in which it provides responses to the questions.
Figure 6 : Grok Homepage
Transparent reasoning in Grok 3 is powered by DeepSearch, whereas BigBrain mode in Grok is instrumental for complex problem-solving. Shown below is the benchmark comparison of GPT-4.5 with Grok-3 and Grok-3 mini.

Figure 7: Grok-3 benchmark comparison [Image Source]
As seen above, Grok-3 outperforms GPT4.5 in Math (15.3 percent higher) and Science (3.6 percent higher) categories! It is available with higher usage quotas for SuperGrok subscribers.
Claude Sonnet 4 (Anthropic)
Claude Sonnet 4 is the successor to Anthropic’s Claude Sonnet 3.7. The model released in February 2025, is available for web, iOS, and Android. Apart from coding, the model is highly efficient in handling high-volume tasks related to user-facing AI assistants.
Claude Sonnet 4 has a context window of 2,00,000 tokens. This essentially means that it can process close to 1,50,000 words in a single interaction. This makes the model ideal for handling analysis of large codebases or extensive datasets.
Visual data extraction, content generation & analysis, and RPA are some of the other use cases that can be efficiently handled by Claude Sonnet 4. You can find more information in the Claude Sonnet 4 official documentation. In case Claude Sonnet 4 does not meet your purpose, you could also try Claude Sonnet 3.7- a slightly older model that is a predecessor of the Claude Sonnet 4 LLM.
Gemini 2.5 (Google)
The Gemini 2.5 models, also termed as thinking models, are capable of reasoning through their thoughts before a response. All of this results in improved performance and higher accuracy.
At the time of writing this blog, the older model Gemini 2.0 Pro & Flash-Lite, the multimodal LLMs that powers the Google chatbot, are available for general use. On the other hand, Gemini 2.5 Pro & Gemini 2.5 Flash are available for preview.

Figure 8: Gemini 2.5 Models
As stated in the Gemini 2.5 Official Blog, Gemini 2.5 Pro leads in math and science benchmarks like GPQA and AIME 2025. All of this can be attributed to its state-of-the-art enhanced reasoning capabilities.
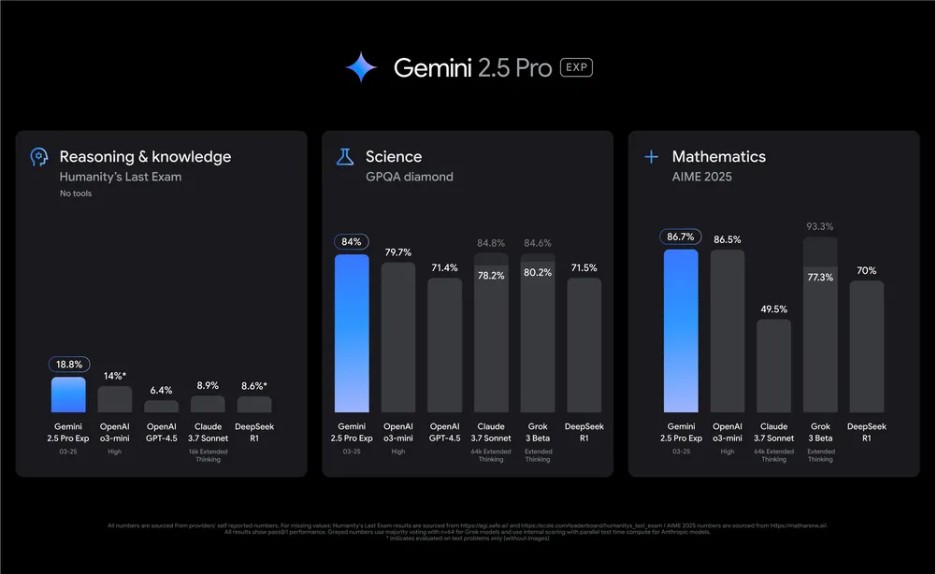
Figure 9: Gemini 2.5 Pro Benchmarks [Image Source]
Gemini 2.5 Pro also excels at creating visually compelling web apps and agentic code applications and achieved a 63.8 percent score with a custom agent setup. Like Gemini 2.0, the latest Gemini models also perform competitively with GPT-4o and Claude 3.5/4 Sonnet, particularly in multilingual applications.
Currently shipped with 1 million token context window, Gemini 2.5 Pro with 2 million token context window is expected to be shipped soon! Gemini 2.5 Pro basic access is free Google AI Studio and Gemini’s web interface, but a paid plan may be required for high-volume or specific use cases.
Jurassic-1, BloombergGPT, Cohere, and ERNIE 3.0 Titan are some of the other closed-source LLMs that did not make it to the list! Whether open-source or proprietary LLM, it is essential to do a thorough research about the model, its capabilities, and relevance to handle the said task(s).
Comparison: Open Source LLMs vs Proprietary LLMs
Scalability, security, community-support (for open-source LLM), model updates, customization, and integration are some of the pointers that should be looked into when making an informed choice. Let’s see how both of them stack against each other:
Cost Comparison
Open-source LLMs are more often perceived as more cost-effective due to the absence of upfront licensing fees. However, you also need to factor-in the variable costs associated with infrastructure, development, inference, and continuous training & maintenance of the LLM.
As per an article by The Information, many startups using open-source LLMs are investing approximately 50~100 percent more in running Meta’s Llama 2 model. This is much costlier in comparison to other closed-source LLMs like OpenAI’s GPT-3.5 Turbo. This is despite a significantly higher upfront investment in producing a top-tier GPT-4.
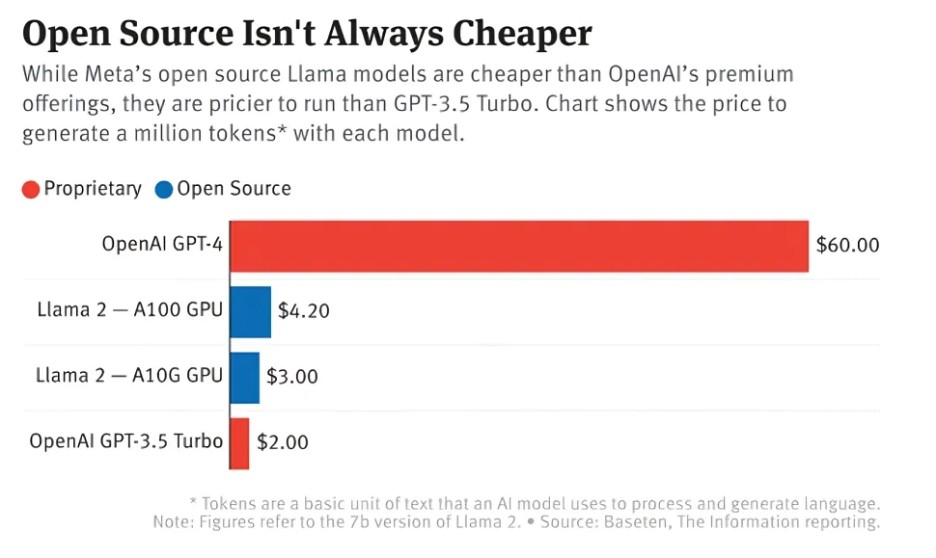
Figure 10: Cost comparison of GPT-4, GPT-3.5, and Llama 2 7B for generating a million tokens [Image Source]
On the other hand, proprietary models normally use a Pay-Per-Use pricing model, where the costs can skyrocket with an increase in the number of input tokens. Mounting costs can later become become prohibitive for high-volume applications.
With every new model release, organizations developing closed-source LLMs focus on improved performance, higher accuracy, and cost reductions when compared to its already released models. For example, GPT-4 Turbo (by OpenAI) is three times faster than GPT-3.5 Turbo but costs much less to run!
Dedicated infrastructure with specialized servers and parallel batch-processing of requests help closed-source LLM providers reduce power usage and running costs. Batch processing is also doable with open-source LLMs but that would require custom implementation and cloud (or on-premise) deployment for distributing workloads across multiple instances or GPUs.
Fine-Tuning & Customization
All the aspects related to an open-source LLM (i.e., model weight, source code, training data, fine-tuning process, etc.) are all available on the internet. This helps in customizing and fine-tuning the LLM as per your use case requirement.
Fine-tuning a pre-trained model helps in minimizing computation costs, reducing carbon footprint, and curtailing efforts involved in training a model from scratch.
Also, most open-source LLMs such as LLaMA, Mistral, or Hugging Face models, support integration with tools & platforms for data processing, storage, automation, collaboration, and more.
On the other hand, internals of a proprietary LLM is restricted due to which there are limited (to no) options for customization and fine-tuning the model. Unlike open-source LLMs, proprietary LLMs are tailored for a particular use case and leverage internal data for fine-tuning and optimization purposes.
Deployment Options
Almost all popular open-source LLMs provide options for public-cloud (e.g, Azure, GCP, AWS, etc.), as well as, on-premise deployment. Additionally, you could also leverage cloud-GPU providers like AceCloud for increased security, reliability, and faster computes through parallel processing.
With open-source LLMs, you have fine-grained control over data privacy and infrastructure. However, a good amount of technical expertise is required for ensuring that the deployed LLMs are secure & optimized to work at scale!
Unlike open-source LLMs, closed-source LLMs are normally deployed via vendor-managed cloud APIs (e.g., AWS, Azure, or proprietary platforms), with on-prem deployments limited to enterprise agreements and project requirements.
Shown below is a high-level diagram that showcases the comparison between Open Source vs Proprietary LLMs:

Figure 11: Open-Source vs. Closed-Source LLMs [Image Source]
Conclusion
Open-source and proprietary LLMs, both have their own advantages and shortcomings—a majority of them are already covered in the guide. Open-source LLMs like Mistral, Llama, DeepSeek-R1, etc. excel at performance, customization, and community support.
On the other hand, proprietary LLMs by OpenAI, xAI, etc. are best-suited for large-scale enterprises that require tailor-made deployment, priority professional support, and adherence to strict compliance practices. A conscious choice needs to be made between open-source and proprietary LLM, taking scalability, budget, security, deployment options, and other factors into consideration.
Businesses can also leverage GPU cloud infrastructure by AceCloud for streamlined, scalable LLM deployments tailored to their needs. Since there is no one-size-fits-all approach for choosing the best-suited LLM, it is recommended to evaluate the LLM from all the aspects mentioned throughout the course of this guide.
Frequently Asked Questions:
Open-source LLMs are AI models whose source code, model weights, fine-tuning procedures, documentation, etc. are freely available for public usage and deployment.
Llama, Mistral, QWEN, DeepSeek-R1, and Gemma are some of the most popular open-source LLMs.
Proprietary (or closed-source) LLMs are AI models that are developed and maintained by organizations, unlike open-source LLMs that are developed & maintained by the community. Source code, model weights, and other aspects of proprietary LLMs are not publicly accessible.
Claude Sonnet 4, GPT-4.5 Orion, Grok 3, and Gemini 2.5 are some of the most proprietary (or closed-source) LLMs.
Cost-effectiveness, community support, customization, fine-tuning, and deployment flexibility are some of the major benefits of open-source LLMs.
Streamlined integration, improved security & compliance, better scalability, and dedicated vendor support are some of the major benefits of proprietary (or closed-source) LLMs.

Related Post










Get in Touch

Credits First!
- 24*7 Human Support
- Pay-as-you-go Pricing
- No Egress Cost
- Multi Tier Security