Choosing between AceCloud and AWS for AI inference is no longer just about cloud brand or headline GPU pricing or who offers the longest service catalog. The real question is simpler and more important: which platform gives you the lowest reliable cost to serve models in production?
Flexera’s 2026 State of the Cloud release says 81% of respondents are using generative AI, while wasted cloud spend rose to 29% for the first time in five years.
That is why the better comparison is total inference economics: monthly serving cost, p99 latency, autoscaling efficiency, deployment complexity and the effort required to keep workloads stable in production.
This matters whether you are serving low-latency chat responses, real-time application requests or batch scoring jobs behind the scenes.
AceCloud vs AWS: Which is the More Cost-Effective Platform?
There is no universal winner. The better fit depends on how your inference workload behaves and how much optimization complexity your team is willing to absorb.
AceCloud is usually more cost-effective when you have:
- Steady GPU-backed inference with predictable utilization.
- Open-source LLM serving on standard NVIDIA stacks.
- India-hosted inference needs where locality matters.
- Stronger need for predictable billing and simpler cost forecasting.
- Lean platform teams that want to reduce provisioning and operating friction.
AceCloud is a stronger fit when you want GPU-first infrastructure, clearer monthly pricing and a more direct path from deployment to production serving.
AWS is usually more cost-effective when you have:
- Bursty traffic with long idle gaps, especially for CPU-oriented or non-GPU inference paths.
- Workloads that can benefit from SageMaker Serverless Inference (CPU / serverless constraints apply) or SageMaker Asynchronous Inference for large payloads and longer processing windows.
- Model stacks that are well suited to Inferentia2 / Neuron compilation and runtime constraints on Inf2.
- An existing AWS footprint across networking, governance, security and MLOps tooling.
- Engineering teams that can actively tune deployment modes and pricing levers.
AWS becomes more attractive when your team can take advantage of its wider chip, service and deployment choices to reduce idle spend or improve price-performance through architecture-level optimization.
AceCloud vs AWS for Production Inference
Once inference moves from testing to production, buyers should evaluate more than instance pricing. The real decision comes down to how each platform behaves under your traffic pattern, architecture and operating model.
| Decision Factors | AceCloud | AWS |
|---|---|---|
| Best-fit workload | Steady GPU-backed inference, consistent utilization | Bursty workloads, mixed patterns, enterprise standardization |
| Accelerator strategy | NVIDIA-first pricing and packaging | Broad choice, including Inf2 (Inferentia2) and NVIDIA GPUs |
| Pricing clarity | Monthly GPU pricing is easy to budget | Pricing is flexible but requires more modeling across services |
| Serverless inference | Typically DIY through your platform stack | SageMaker Serverless Inference is useful for intermittent CPU-based inference with tolerance for cold starts, but it is not a GPU inference option and does not support VPC configuration |
| Egress economics | Highlights no egress charges, which makes cost forecasting easier | Egress varies by region and service, requires explicit modeling |
| Platform operations | GPU VMs plus Kubernetes or your serving layer | SageMaker endpoints reduce infra tasks but add platform behaviors |
| Lock-in risk | Common NVIDIA stacks can reduce portability friction | Neuron and managed endpoints can increase dependency over time |
| India-centric deployment | Clear India region monthly pricing is visible | Strong India presence, however cost modeling can be more complex |
| Time-to-first-endpoint | Often faster for teams already serving on NVIDIA | Often faster if your org already runs SageMaker workflows |
| Cold-start / latency predictability | Better suited to always-on GPU serving where latency behavior is easier to keep consistent | SageMaker Serverless can reduce idle cost for compatible workloads, but cold starts and feature exclusions must be modeled explicitly; AWS documents Provisioned Concurrency as the way to keep endpoints warm and reduce startup latency. |
| Procurement & billing complexity | Simpler public pricing posture and India-friendly budgeting clarity | Broader service choice, but pricing often requires modeling across compute, networking and managed services |
| Quota / time-to-provision | Public positioning emphasizes faster GPU access and simpler procurement motion | Availability can depend on region, quotas, architecture and internal AWS setup |
Key Takeaways:
- AceCloud is often the better choice when pricing clarity, NVIDIA portability and a straightforward production path matter most.
- AWS is often the better choice when your team can actively exploit optimization levers across chips, service layers and deployment modes.
What Should You Compare Beyond Hourly GPU Pricing?
To compare AceCloud and AWS fairly, you need to evaluate the broader cost structure behind production inference, not just GPU rates.
1. Compute and accelerator choice
The first question is not price. It is fit.
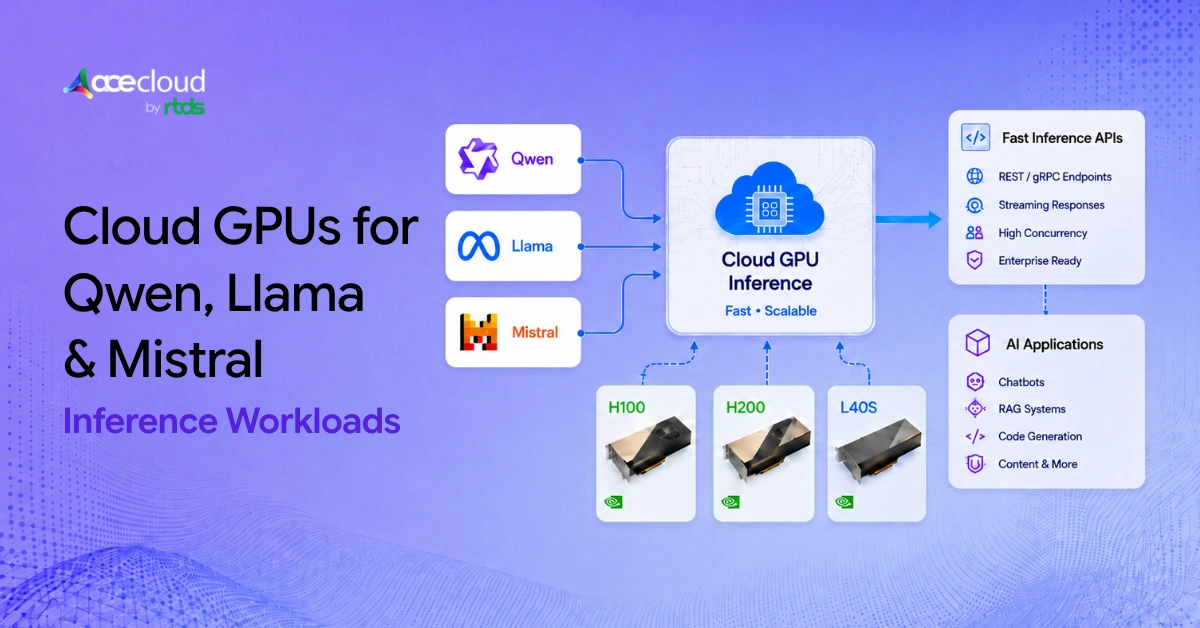
AceCloud’s AI infrastructure story is centered on standard NVIDIA GPUs such as L40S, L4, A100 and H100. That is attractive for teams already building around familiar serving stacks and NVIDIA-optimized tooling.
AWS gives teams a broader accelerator menu. That includes standard NVIDIA GPU-backed options as well as Inferentia2 on Inf2, which can improve price-performance only when the model, precision, runtime behavior, and operator workflow fit the AWS Neuron toolchain well enough to justify compile / porting effort and reduced portability. However, the value depends on model compatibility, engineering readiness and how comfortable your team is with the Neuron software stack.
That means the right comparison is not just GPU vs GPU. It is also portability vs platform-specific optimization.
2. Idle-time economics
This is where many buyers miscalculate.
If your traffic is spiky, the cheapest hourly instance may still produce a higher monthly bill because capacity sits warm for too long. In these cases, AWS can become more cost-effective when CPU-oriented Serverless Inference, Asynchronous Inference, or other autoscaled endpoint patterns reduce idle infrastructure time.
For GPU-backed inference, you should compare real-time endpoints, EKS / EC2 serving, or Inf2-based deployments instead of assuming SageMaker Serverless applies.
3. Batch versus online inference
Not every inference workload should be judged by the same framework.
If you are serving user-facing, low-latency requests, warm capacity, autoscaling behavior and latency consistency matter more. If you are running offline scoring or scheduled jobs, the evaluation changes. In that case, queueing tolerance, payload size, throughput and execution pattern matter more than p99 response time.
This is important because a platform can look expensive in one serving mode and cost-effective in another.
4. Orchestration overhead
Managed infrastructure is not free just because it is convenient.
If you are running Kubernetes-based serving, orchestration becomes part of the bill. It also becomes part of the team burden. AWS can reduce some infrastructure handling through managed options, but those conveniences often introduce added service-layer complexity or extra pricing dimensions.
AceCloud’s positioning is more straightforward for teams that want GPU infrastructure plus a familiar serving path without layering too many cloud-specific decisions on top.
5. Data transfer and surrounding charges
Surrounding costs often decide the real winner.
A platform may look cheaper at the compute layer, then become more expensive once data transfer, networking patterns, endpoint architecture, monitoring overhead and support expectations are factored in.
Buyers who care about forecast accuracy should evaluate the whole bill, not just the accelerator line item.
6. Team overhead
A platform that takes longer to provision, tune and maintain can become more expensive even if its raw compute economics look attractive.
For growing AI teams, time-to-value matters. So does the number of decisions required before a model becomes stable in production. This is where operational simplicity becomes a cost factor, not just a convenience factor.
What Teams Should Validate Before Choosing?
Before choosing an inference platform, teams should validate the technical and operational factors that shape real-world cost and reliability.
Runtime and tooling fit
If your team already deploys through standard NVIDIA-based stacks such as vLLM, Triton, TensorRT-LLM or other familiar open-source pathways, AceCloud can reduce adaptation effort. If you are evaluating Inf2, validate how well your model, framework and deployment pattern fit the Neuron ecosystem before assuming lower cost automatically means lower total effort.
Latency and warm-capacity behavior
If your workload is user-facing, cost should be modeled alongside latency predictability. Cold-start tolerance, warm endpoint expectations and scaling behavior can change both user experience and monthly economics.
Autoscaling behavior under real traffic
Do not evaluate autoscaling from product pages alone. Test how the stack behaves under actual concurrency, burst conditions and queue pressure. The cheapest architecture on paper can become the most expensive if it scales late, overprovisions, or creates unstable latency under load.
Operational control vs managed abstraction
Some teams want maximum control over serving infrastructure. Others want to reduce infrastructure handling and accept more platform abstraction. The right choice depends on your team size, engineering maturity and production expectations.
Portability over time
Lock-in is not only a strategic issue. It is also a cost issue. If moving models, images, runtimes or serving patterns later becomes difficult, your future operating choices narrow. Teams that want long-term flexibility should weigh this more carefully than they often do at the start.
Cost Model Breakdown: What Actually Drives the Bill?
The most useful question is not, “Which platform is cheaper?”
It is, “Which platform gives this workload the lowest fully loaded monthly cost?”
In practice, the answer usually comes down to five things:
- accelerator fit
- idle behavior
- orchestration overhead
- surrounding charges such as egress and support
- the team time required to keep inference reliable
A simple budgeting example makes this easier to understand.
If you are running a 24/7 inference endpoint and keeping a GPU warm all month, fixed monthly GPU pricing is easier to forecast and explain internally. AceCloud’s GPU pricing gives buyers a clearer starting point for that kind of planning.
If your demand is bursty, or your workload can genuinely benefit from serverless patterns, asynchronous flows or platform-specific accelerator optimization, AWS may reduce waste more effectively. However, that outcome depends on architecture discipline, compatibility and correct workload mapping.
In other words, AceCloud often simplifies the baseline. AWS can outperform when the workload shape rewards active optimization and the team is equipped to capture that value.
A Practical Cost Checklist Before Choosing
Before selecting either platform, validate the following:
- Check accelerator fit first. Inferentia2 can improve price-performance, but NVIDIA-based stacks may be easier to port and operate.
- Model idle time honestly. Always-on endpoints and spiky endpoints should not be priced the same way.
- Count orchestration overhead. If you are using EKS. Amazon EKS adds a control-plane fee of $0.10 per cluster-hour under standard Kubernetes version support and $0.60 per cluster-hour under extended support. This fee does not apply to SageMaker AI endpoints or plain EC2 inference unless you are also operating EKS.
- Track surrounding charges. Egress, migration and support costs change the real monthly number.
- Treat team time as cost. A platform that is harder to provision, optimize and maintain can erase apparent savings. This last point is an editorial inference based on each platform’s public operating model.
Portability and Lock-In Matter More Than They Seem
Price-performance is only one part of the decision.
AWS can be highly attractive when its service mix and accelerator options line up with the workload. But that value may come with deeper dependency on AWS-native patterns, managed endpoint behavior or the Neuron ecosystem.
AceCloud is more closely aligned with standard NVIDIA-based deployment patterns. For teams that want easier portability across tools, images, runtimes and serving stacks, that can matter as much as monthly pricing.
For many growing AI teams, flexibility is not a secondary concern. It is part of cost control.
Ready to Simplify AI Inference Costs with AceCloud?
Choosing between AceCloud and AWS for AI inference is not just about who offers the lowest listed price. It is about which platform fits your traffic pattern, your architecture and your team’s ability to keep serving efficient in production.
If your workload depends on steady GPU-backed inference, predictable budgeting and a simpler path to deployment, AceCloud offers a practical advantage. Its GPU-first approach, clearer pricing posture and alignment with standard NVIDIA-based serving make it easier for teams to move from experimentation to production without adding unnecessary complexity.
Explore AceCloud to estimate your serving cost, evaluate workload fit and choose infrastructure that supports both performance and long-term efficiency.
Frequently Asked Questions
AceCloud is often cheaper for steady GPU-backed inference when predictable monthly pricing and simpler egress assumptions matter. AWS is often cheaper for bursty traffic when serverless scaling and deep platform integration reduce idle spend.
Inferentia2 can be cheaper when your model and serving stack fit the Neuron toolchain well enough to benefit from Inf2’s price-performance profile. But the evaluation should include model compilation requirements, feature support and portability tradeoffs, because those can change both engineering effort and long-term platform flexibility.
AceCloud can be a strong fit when your users are primarily in India and you want simpler locality planning with clear India region pricing. You should still validate required compliance controls and network design for your specific workload.
Idle replicas, scaling inefficiencies, data transfer out and the engineering hours required to keep endpoints stable tend to dominate. You can reduce these costs by measuring throughput under load, tuning autoscaling policy and tracking egress economics as part of monthly serving cost.
You should choose SageMaker when managed deployment reduces your team’s operational burden more than it increases platform cost. Serverless Inference is a fit for intermittent traffic that can tolerate cold starts, while Asynchronous Inference is better suited to large payloads or longer-running requests that do not need an immediate synchronous response. GPU VMs make more sense when you want tighter infrastructure control, standard NVIDIA portability or a simpler always-on serving model.