
Databases are an integral part of any application, as they provide persistent storage for application data. Teams and organizations have the option to choose from closed-source and open-source databases based on their budget, security, and long-term stability requirements.
Open-source databases like MySQL, PostgreSQL, Redis, etc. are widely used by large-scale organizations due to their flexibility, security, community support and ability to be customized for diverse application needs. In this blog, we look at the top ten open source databases along with deep diving into the essentials of Database-as-a-Service (DBaaS) for reducing operational complexity and management overhead.
What Are Open Source Databases
As the name suggests, open-source database systems are databases whose source code is publicly available to use, modify, and distribute under the appropriate open-source licenses. As the source code is available, developers can modify the DB code as per their technical requirements.
These databases offer relational, document, key-value, column-family, and graph storage, among other data formats and use cases. As seen in DB-Engines ranking, five of the world’s top 10 databases are open source (as per data dated December 2025).
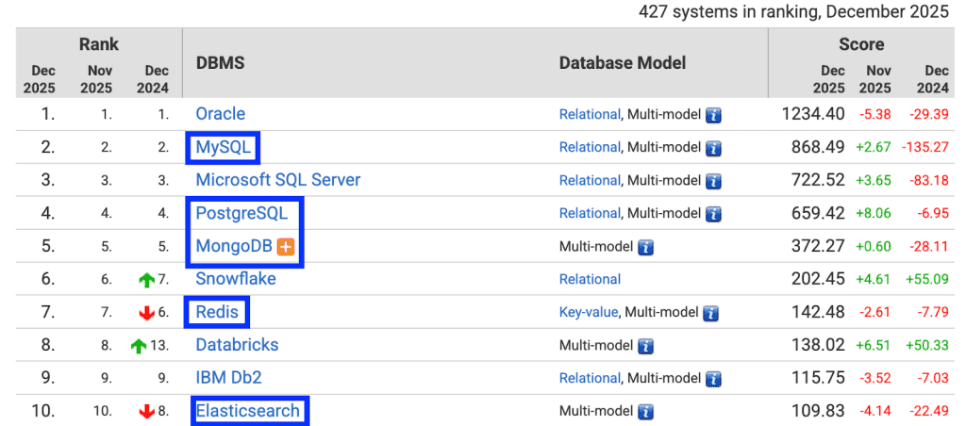
Figure 0 – Open-Source Databases in DB-Engines Ranking [Image Source]
Open source databases are extensively used industry-wide, as they provide openness, flexibility, affordability, and robust community support.
Benefits of Open Source Databases
Apart from licensing and costs, there are umpteen benefits of open source databases in comparison to commercial databases, some of the major benefits are listed below:
- Customization Options: As the source code of an open-source database is publicly available, developers can customize as per the specific requirements, thereby enhancing functionality and performance.
- Community Support: Like any other open source project, community is one of the core pillars of open-source databases. Active community participates in pushing features, fixing bugs, and updating documentation.
- No Vendor Lock-In: Enterprises and teams are not tied to a particular vendor when using an open source database. It is easy to migrate to another open-source database in case the current one does not meet the expected performance (or scale).
Top Ten Open Source Databases
Listed below are the top ten open source databases (listed in no particular order). By the end of this list, you would be in a position to shortlist a few database options that best suit your project or product requirements.
1. MySQL
MySQL is one of the most widely used open-source Relational Database Management Systems (RDBMS). This open-source database is hugely popular for web application development. According to a 2025 Stack Overflow Developer Survey, MySQL holds close to 40.5 percent popularity among all the survey respondents.

Figure 1: MySQL in 2025 Stack Overflow Developer Survey [Image Source]
Large technology enterprises, including Meta (formerly Facebook), X (formerly Twitter) and Booking.com, rely on MySQL for their high-volume systems. Generative AI has also been integrated into MySQL through features collectively referred to as MySQL AI.
AutoML in MySQL AI simplifies the ML processes and the GenAI capabilities used in in-database LLMs help in data retrieval and generation (or summarization) of content. You can find more information about MySQL AI in the official MySQL Downloads Page.
At the time of writing this blog, the latest version of MySQL is 8.0.44. MySQL is available in multiple download editions, each designed for different use cases:
- MySQL Community Edition – Free and open-source edition of MySQL
- MySQL Enterprise Edition – Commercial edition offered by Oracle
- MySQL Cluster (NDB) – Designed for high availability and real-time workloads
- MySQL Embedded Edition – Designed for usage by OEMs and ISVs
- MySQL HeatWave (Cloud Edition) – Cloud-optimized MySQL offering
MySQL is available as a service on all major cloud platforms, including the managed database solution from AceCloud. Managed cloud databases from AceCloud simplify cloud database management with auto-scaling, enterprise grade security and transparent pricing.
Features
MySQL is dual-licensed under the GPL version 2 open source license. Here are some of the salient features of MySQL:
- Relational database management system (RDBMS) with structured tables, schemas, and full SQL support
- Cornerstone of the LAMP stack of OSS technologies, namely Linux, Apache, MySQL and PHP, Perl or Python
- ACID (Atomicity, Consistency, Isolation and Durability) compliant transactions for ensuring data integrity and reliability
- Cross-platform support, including Linux, macOS, and Windows
- Support for a wide range of web applications
- Exhaustive security features such as RBAC, user authentication, SSL/TLS support, etc.
- Wide community support and a mature ecosystem of tools for observability, backup, migration and operational management
- AI-driven capabilities through MySQL HeatWave
Architecture
MySQL follows a client-server architecture. The client connects to the server via standard security protocols. The server is organized into layered components, starting with the connection and authentication layer. This layer manages user access, security and session handling.
Query parsing, optimisation, and execution are handled by the server core. Data retrieval and storage are managed by storage engines. Owing to the pluggable storage engine architecture, customers can select the appropriate engine that meets their requirements. Primary–replica replication (asynchronous or semi-synchronous) is supported for data redundancy and fault tolerance.
Major Use Cases
- Web application development and online transaction processing (OLTP)
- Widely used in platforms related to social media, Content Management Systems (CMS) and e-commerce
- Commonly used as the database layer for web and cloud applications
2. PostgreSQL
PostgresSQL is one of the most widely used open-source Relational Database Management Systems (RDBMS). It supports advanced data types like JSON, XML, and key-value pairs. PostgreSQL is popular for its exceptional in-memory performance and reliability.
According to the 2025 Stack Overflow Developer Survey, PostgreSQL is the most popular open-source database and holds close to 55.6 percent popularity among all the survey respondents.

Figure 2: PostgreSQL in 2025 Stack Overflow Developer Survey [Image Source]
As PostgreSQL supports complex queries and rich data types, it is ideal for handling transactional and analytical workloads. Akin to MySQL, PostgreSQL is also ACID compliant, thereby ensuring strong data integrity and reliable handling of transactions. PostgreSQL also provides several index types, including B-tree, Hash, GiST, SP-GiST, GIN, and BRIM.
At the time of writing this blog, the latest version of PostgreSQL is v17.
Multi-Version Concurrency Control (MVCC) in PostgreSQL helps improve database performance in a multi-user environment. PostgreSQL is available as a service on all major cloud platforms, including the managed PostgreSQL solution from AceCloud. Managed PostgreSQL databases from AceCloud simplify cloud database management, optimize performance, and let the team use PostgreSQL without any operations overhead!
Features
PostgreSQL is released under the permissive PostgreSQL License.Here are some of the salient features of PostgreSQL:
- Strong SQL standards compliance
- ACID compliant transactions
- Support for JSON and semi-structured data, enabling hybrid relational and NoSQL workloads
- Cross-platform support, including Linux, macOS, and Windows
- Rich indexing options and strong concurrency control using MVCC
- Security mechanisms like RBAC, user authentication, SSL/TLS support, etc. in place
- Long-term stability and open-source community support
Architecture
Like MySQL, the PostgreSQL open-source database also follows a client-server model. The server process is responsible for managing the database files, accepting incoming connections, and performing database connections. The database server program is termed as postgres.
Client applications can either be a text-oriented tool, a GUI application, or a web server that accesses the DB to display the web pages. On the lines of a client-server architecture, both the client and server can be on different hosts.
The PostgreSQL server has the capability to accept multiple concurrent connections from different hosts. You can find more detailed information about the architecture in the PostgreSQL official architecture documentation.
Major Use Cases
- Applications that involve complex database query processing
- Enterprise and transactional applications like financial systems and scientific research
- Data warehousing and analytics
- AI and data-driven applications
- Geospatial applications that require support for Geographic Information Systems (GIS), enabled through PostGIS
- Commonly used as the database layer for web and cloud-native applications
3. MariaDB
MariaDB (or MariaDB Server) is a popular open-source RDBMS that is created by the original MySQL developers. The database was designed as a backward-compatible, drop-in replacement for MySQL. This would make the transition from MySQL to MariaDB very seamless. Applications, connectors, and scripts implemented for MySQL work without any modifications with the MariaDB database.
MariaDB is the default database in most Linux distributions. Like other open-source databases, MariaDB Server supports various indexing options, including B-tree, hash, and full-text indexes. MariaDB also supports all major programming languages and works on any server operating system.
This enterprise open source database also provides database services to support scalability, mission-critical deployments, and more. Since MariaDB is a drop-in replacement for MySQL, it uses the same default ports (i.e., 3306), sockets, and service names. While MariaDB can be installed alongside MySQL, it is recommended to uninstall MySQL to prevent port and configuration conflicts, especially in production environments.
Features
MariaDB is licensed under GPL v2. Its latest LTS release MariaDB 11.4 offers stability and long-term support for production workloads. Here are some of the salient features of the MariaDB server:
- High compatibility with MySQL clients and tools
- Top-notch performance, security, and scalability that is primarily optimized for handling large datasets and modern workloads
- Built-in security features such as RBAC, authentication plugins, SSL/TLS, etc.
- Availability of pluggable storage engines like InnoDB, Aria, ColumnStore, and MyRocks, each optimized for specific database workloads (e.g., analytics, high-volume writes, etc.)
- Support for replication, Galera Cluster, and automatic failover
- Support for Hybrid Transactional/Analytical Processing (HTAP) that combines row-based storage (for fast OLTP transactions) and columnar storage (for quick OLAP analytics) in a single database
- Active open-source community participation and support, particularly from the passionate MySQL user and developer community
Architecture
Like other open-source database engines, MariaDB Server (or MariaDB) also follows a modular architecture. The top layer is the client layer that is responsible for handling connections from applications using standard MySQL-compatible protocols.
The server core handles query parsing, optimization, transaction management, security, and execution. Storage engines in MariaDB manage storage and retrieval of data. Though the default storage engine is InnoDB, the MariaDB server supports multiple storage engines, including Aria, MyISAM, ColumnStore, Spider, MyRocks, etc.
These multiple storage engines in MariaDB are tailored for transactional, analytical, and specialized workloads. You can find detailed information about the architecture in the MariaDB architecture documentation.
Major Use Cases
- Web applications and online transaction processing (OLTP)
- MariaDB Server is one of the preferred open-source database for usage in platforms related to social media, Content Management Systems (CMS) and e-commerce
- Business-critical applications that require ACID compliance, reliability, and strong consistency
- Cloud-native and containerized applications
- Write-heavy applications that require extensive logging, event tracking, and high data ingestion rates
MariaDB is often chosen as a drop-in replacement for MySQL. You can harness the potential of MariaDB by opting for Database-as-a-Service (DBaaS) from AceCloud, as it lets you spin up cloud databases in minutes, while eliminating the need for manual database management.
4. MongoDB
MongoDB is a popular NoSQL database used for storing and managing structured, semi-structured and unstructured data. MongoDB uses a document-oriented data model where the data is stored in JSON-like documents that are in-turn grouped into collections.
According to the 2025 Stack Overflow Developer Survey, MongoDB holds close to 24 percent popularity among all the survey respondents.

Figure 3: MongoDB in 2025 Stack Overflow Developer Survey [Image Source]
As the data is not stored in fixed tables, MongoDB makes it easier to handle unstructured or semi-structured information without any changes in the DB schema. MongoDB stores data in a type of JSON format called BSON (Binary JSON).
Like other popular databases, MongoDB now supports ACID transactions, including multi-document transactions (introduced in later versions) in addition to its long-standing single-document atomicity. Querying, indexing, and data aggregation are some of the salient features of the MongoDB database. Aggregation operations in MongoDB can be used for the following:
- Group values from multiple documents together
- Perform operations on the grouped data and get a single results
- Analyze data changes that have happened over a period of time
- Query the most up-to-date version of the data
Hence, aggregation in MongoDB helps with advanced querying capabilities, including filtering, grouping, and data processing on-the-fly. MongoDB integrates with popular programming languages, including JavaScript / Node.js, Python, Java, Ruby, C#/.NET, amongst others.

Sharding in MongoDB distributes data and workloads across multiple nodes, thereby helping with horizontal scaling and higher throughput.
Figure 4: Sharding in MongoDB [Image Source]
On similar lines, MongoDB also supports popular frameworks and platforms like Express.js, NestJS (Node.js ecosystems), Django, Flask, FastAPI (Python), Spring Boot (Java), Ruby on Rails (Ruby), and more.
MongoDB is extensively used in CMS, real-time analytics, IoT platforms, and AI-driven applications.
Features
MongoDB is licensed under the Server Side Public License (SSPL) and the code is available onGitHub. SSPL is a source-available license that is not OSI-approved, so some organizations treat MongoDB as open-core rather than classic open-source.At the time of writing this blog, the latest version of MongoDB is v8.0
- Document-oriented data model with the data stored in a JSON type of a format called BSON
- Support for dynamic queries, indexing, and aggregation
- Horizontal scalability through sharding where the data and workloads are distributed across multiple nodes (or servers)
- Replica sets in MongoDB provide redundancy and high availability. Replication provides a level of fault tolerance against the loss of a single database server
- Strong developer ecosystem and support for a wide range of frameworks and programming languages
Architecture
MongoDB follows a distributed, document-oriented architecture. Data in the BSON format is stored inside collections instead of fixed tables. This is the document storage layer.
Rich queries, aggregations, and secondary indexes on document fields are made possible by the query and indexing layer. As stated earlier, replica sets are used in MongoDB where data is replicated across multiple nodes with automatic failover.

Figure 5: MongoDB Architecture [Image Source]
As seen in the MongoDB architecture diagram, data is partitioned across multiple shards [Shard 1… Shard N] for distributing load and storage. mongos router processes abstract the complexity of the distributed system and direct client requests to the appropriate shard, with config servers storing cluster metadata.
Routers in MongoDB abstract the complexity of the distributed system and direct client requests to the appropriate shard. With this architecture, MongoDB can readily scale out without sacrificing fault tolerance or performance.
Major Use Cases
- Schemaless document storage
- Managing dynamic content structures for CMS
- Big Data applications
- Used for product catalogs, inventory management, and personalization data in e-commerce platforms
- Supports microservices architecture by enabling each service to own its data model
- AI and data-driven applications where MongoDB is used for storing unstructured data, metadata, and application data for ML pipelines
5. FerretDB
FerretDB, built on PostgreSQL, is an open-source alternative to the popular MongoDB database. FerretDB lets you use MongoDB drivers seamlessly with PostgreSQL as the database backend.
FerretDB stores data in PostgreSQL, allowing new or existing PostgreSQL instances to function as a document database compatible with MongoDB workloads. Like other popular open-source databases, FerretDB can also be deployed on-premise or run from the cloud.
At the time of writing this blog, the latest version of FerretDB is v2.7. The FerretDB installation guide provides step-by-step information on installing FerretDB as per your requirements. As FerretDB implements the MongoDB wire protocol, it supports most common MongoDB features that are used in everyday applications.
Features
FerretDB is fully open-source and released under the Apache License 2.0, making it an attractive option for enterprises seeking alternatives to MongoDB’s licensing model. Here are some of the salient features of the FerretDB:
- MongoDB wire-protocol compatibility lets existing MongoDB drivers and tools to work without application code changes
- JSON-like document storage and querying
- Data durability, reliability, and consistency inherited from the PostgreSQL-based storage
Architecture
FerretDB also follows a layered architecture. The top layer consists of the MongoDB wire protocol that lets existing MongoDB drivers and tools connect without any changes in the implementation.
FerretDB’s query translation layer parses and translates the incoming MongoDB-style queries from the top layer. These are then converted into SQL statements and executed on PostgreSQL that also acts as a persistent storage engine.
In the architecture, FerretDB acts as a middleware layer that bridges document-oriented APIs with relational storage.
Major Use Cases
- Prototyping and testing MongoDB-compatible applications in open-source setups
- MongoDB workload migration for moving away from MongoDB licensing while harnessing the potential of the MongoDB-compatible drivers and APIs
- Applications that require modernization of legacy systems
In summary, FerretDB works best with document workloads that are compatible with MongoDB and prioritise PostgreSQL stability, open-source license, and infrastructure reuse.
6. Redis
Redis is a highly popular open-source in-memory key-value data store that also doubles up as a database, cache, and message broker. The core Redis engine (often referred to as Redis Open Source in the docs) was historically released under a permissive open-source license. Newer Redis releases use Redis’s own source-available licensing model rather than a traditional OSI-approved license. Prior to release v8.0, Redis Open Source was referred to as Redis Community Edition (Redis CE).
Redis open-source database is preferred by developers who are building real-time data-driven applications and using cloud-native and microservices architectures that require low latency and high performance. Redis has the most feature-rich cache, data structure server, and document and vector query engine.
Like other popular open-source databases discussed so far, Redis also has support for multiple data structures like strings, lists, streams, etc. Redis is primarily used for session management, caching, real-time analytics, and leaderboards.
The Redis Data Integration (RDI) helps enable modern caching mechanisms where the data from the DB is synchronized into Redis in near real-time. This ensures that only the latest data is read, avoiding stale data and resulting in fewer cache misses when the database is accessed.
High availability through replication and support for data persistence are some of the key features of the Redis open-source database. The source code of Redis Open Source is hosted on GitHub. At the time of writing this blog, the latest version of Redis Open Source is v8.4.0
Features
- Redis uses efficient data structures and keeps the data in memory. This fastens the access, leading to sub-millisecond latency for R/W operations
- High performance, low latency best-suited for modern real-time web applications
- Redis is highly extensible due to the availability of Redis Modules APIthat makes it easy to implement new Redis commands
- Distribution of data across multiple nodes with replication and automatic failover results in high availability in Redis Cluster
- Redis provides client libraries in popular programming languages (e.g., JavaScript / Node.js, Python, Java, Ruby, C#/.NET, etc.) that lets you connect your application seamlessly to Redis.
- Apart from Redis client libraries, Redis also has community-supported client libraries in additional languages
- Rich set of features such as pub/sub messaging, geospatial indexing, and scripting
Architecture
Redis follows a single-threaded, event-driven model and handles multiple clients via non-blocking I/O operations. A master-slave replication model is used for data redundancy, where the primary nodes process the write operations and the replicas are responsible for serving read operations.
As stated earlier, Redis stores all the data in memory for faster R/W operations. Clients communicate with the Redis DB via the TCP-based protocol. Redis provides a range of data persistence options such as RDB (Redis Database), AOF (Append Only File), and RDB + AOF. You can find more details in the official Redis persistence documentation.
Automatic failover and instance monitoring are handled by Redis Sentinel. Redis Cluster uses hash slots to distribute data among several nodes for horizontal scalability.

Figure 6: Redis Cluster Architecture [Image Source]
In many projects, Redis is used alongside the MySQL database where MySQL stores the data and Redis accelerates real-time DB operations by acting as an in-memory cache or real-time data layer to improve performance.

Figure 7: Redis + MySQL [Image Source]
In a nutshell, Redis architecture is designed such that Redis can scale while maintaining performance, reliability, and simplicity.
Major Use Cases
- Integration with Generative-AI applications (e.g. LangGraph, mem0) for short-term memory, long-term memory, LLM response caching (semantic caching), and retrieval augmented generation (RAG)
- Redis can be used for search and query engines due to its support for Redis Query Engine indexing. This can be used for hash/JSON documents, vector search, full-text search, geospatial queries, ranking, and aggregations
- Redis can also be used as a NoSQL data store by storing structured, schema-less data and providing accelerated access
- Real-Time Analytics for personalization, recommendations, fraud detection, and risk assessment
You can find more Redis use cases in the Redis Key use cases official documentation. The in-memory data store aspects of Redis can be complemented by using it with traditional databases (e.g., MySQL) for delivering low latency response for modern web applications.
7. SQLite
SQLite is a serverless, small, fast and self-contained database engine. Its implementation is written in the C Language. According to a 2025 Stack Overflow Developer Survey, SQLite is the 3rd-most popular database among all the survey respondents.

Figure 8: SQLite in 2025 Stack Overflow Developer Survey [Image Source]
As the name suggests, SQLite is a light-weight database which is highly efficient with local storage. Due to this, SQLite is extensively used in desktop applications and low traffic web apps. SQLite is the default local database on iOS and Android.
SQLite is also ACID compliant and the entire database is stored in a single file. Apart from low memory footprint, a single DB file makes copying, deploying, and managing the DB a simple task.
Since SQLite is a serverless database, it is best suited for local storage, prototyping, and testing applications that do not have huge database requirements.
Features
- SQLite database does not have a server component. The entire database runs directly within the application
- There is zero custom configuration required to install SQLite
- Schema and data is stored in a single (.sqlite) file
- SQLite is available for Windows, macOS, and Linux
- Common operations like joins, triggers, indexes, etc. are all supported on SQLite
Architecture
SQLite follows an embedded database model. The SQL Compiler in the database validates the syntax and semantics.
The Storage Engine Layer manages records, tables, and indexes using B-trees. As stated earlier, the entire data is stored in a single file which is of the .sqlite format.
Major Use Cases
- Desktop applications
- SQLite is extensively used in embedded hardware devices and IoT due to its low memory footprint
- Offline-first applications
8. ElasticSearch
ElasticSearch is a distributed search and analytics engine, scalable data store and vector database. It is optimized for relevance and speed for handling production workloads.
ElasticSearch lets you perform vector search and search massive datasets in near real-time. It can also be seamlessly integrated with Generative-AI applications. The data is stored as JSON documents and a RESTFul API is exposed by ElasticSearch for effortless integration with the applications.
ElasticSearch can be scaled horizontally and data can be distributed across different nodes in a cluster. It is also used for observability, as ElasticSearch can collect, store, and analyze logs and metrics from distributed systems.
When run individually as a standalone single-node service, ElasticSearch can be accessed through the REST APIs. Apart from being used as a standalone search or analytics engine, ElasticSearch can also be deployed as a part of ELK stack along with Kibana.
Features
NetFlix, GitHub, and Uber are some of the large enterprises using ElasticSearch for search and analytics. The latest LTS version of Elasticsearch is Elasticsearch 9.2.3. Here are some of the salient features of ElasticSearch:
- Provides powerful query language called Query DSL for realizing complex searches
- ElasticSearch offers schema-light indexing due to its document-oriented storage where data is stored as JSON documents
- Highly scalable and distributed, as data split in shards is further distributed across different nodes for horizontal scaling
- Provision of simple REST APIs simplifies integration with applications
Architecture
ElasticSearch follows a distributed, cluster-based architecture designed for scalability and fault tolerance. A cluster of nodes is used for storing and searching the data. All nodes share the same cluster name and collectively store and search data.
Every node that has different roles (e.g., master-eligible nodes, data nodes, ingest nodes, etc.), is a running instance of ElasticSearch. Data is stored in the JSON format using a document-oriented approach, where each document is considered to be a self-contained record.
Index, a logical namespace for documents, is divided into numerous shards for improved scalability. Inverted index is leveraged in ElasticSearch for fast full-text searches.
Major Use Cases
- Best-suited for applications that require extremely fast search and analytics
- Ideal for usage in CMS due to its capability to efficiently handle unstructured data
- Log analytics and observability which helps team periodically monitor system health and troubleshoot issues
- DevSecOps can leverage ElasticSearch for detecting threats, analyzing security events, and investigating incidents using the large volumes of log data
- ElasticSearch is extensively used for location-based searches (e.g., maps, geo-filtering, etc.)
9. Apache Cassandra
Apache Cassandra is an open-source NoSQL database that can help in managing massive amounts of data with ease. There is no single point of failure, as Cassandra streams data between nodes during scaling operations.
Optimized for high write throughput and low-latency operations, zero copy streaming in Cassandra makes it 5x times faster without virtual nodes (vnodes) particularly in cloud and Kubernetes environments.
As Cassandra offers tunable consistency levels, it lets users balance between consistency and performance. Like many other open-source databases, Cassandra is also horizontally scalable, due to which seamless addition of nodes is possible while ensuring zero DB downtime. This linear scalability enables Cassandra to handle large volumes of data across different nodes.
Features
At the time of writing this blog, the latest stable version of Cassandra is 5.0.6. The entire source code of Cassandra is hosted on GitHub.
- Peer-to-peer modelled architecture ensuring that there is no single point of failure
- High fault tolerance through automatic data replication across multiple nodes
- Optimized for high-volume, write-intensive workloads. Cassandra is capable of handling millions of writes/second, making it ideal for logging, metrics collection, and sensor data ingestion
- Storage engine and data model in Cassandra are best-suited for efficiency handling time-series and append-only workloads
- Active open-source community support
Architecture
Apache Cassandra follows a P2P distributed architecture. All the nodes are considered equal and there is no single master node.
Data is distributed to the nodes that are a part of the cluster using a hashing mechanism called as consistent hashing. Each piece of data is hashed with the help of a partition key and the resulting hash determines the respective node in the logical ring that would be storing the data.
For improved fault tolerance and ensuring high node availability, data is replicated across all the nodes. Cassandra also supports multi-data center replication, allowing data to be replicated across geographically distributed data centers.
Major Use Cases
- Usage in IoT and telemetry platforms owing to Cassandra’s ability to efficiently handle massive amounts of data
- Ideal for usage in real-time dashboards and analytics pipelines due to Cassandra’s low latency reads and writes
- Cassandra is widely used in messaging and event-driven systems such as chat applications, event streaming backends, etc.
- Ability to process continuous data streams makes Cassandra ideal for usage in domains like fraud detection and risk analysis
10. Neo4j
Neo4j is a NoSQL graph database that is built to support most challenging transactional and analytical workloads. Neo4j uses graph structures with nodes, edges, and properties for representing and storing data.
Neo4j Graph Database is available with multiple deployment options like self-hosting, hybrid, multi-cloud, and fully-managed cloud service.
With Neo4j Graph Database, you can choose from multiple cloud options – self-hosted, hybrid, multi-cloud, or our fully managed cloud service named Neo4j AuraDB. Like other databases, Neo4j Graph Database is also ACID compliant and provides a powerful query language called Cypher to efficiently handle complex queries.
Neo4j also has built-in replication and clustering for high availability. Neo4j is licensed under the GPL-3.0 license and the code is available on GitHub.
Features
- ACID compliant transactions
- Graph Database built around nodes, relationship and properties
- Offers REST and Java APIs for integration with other applications
- Provision of Cypher query language for retrieving graph data
- High availability clustering for scalability and fault tolerance
Architecture
Neo4j follows a native graph database architecture. The native graph storage engine stores nodes, relationships, and properties on disk without any usage of tables or joins. Key-value properties hold details of nodes and relationships.

Figure 9: Neo4j Graph Data Platform Architecture [Image Source]
Casual clustering is used to ensure improved scalability and high availability. The Cypher query engine translates graph queries into efficient execution plans optimized for graph traversal.
Major Use Cases
- Neo4j is ideal for applications that require deep and complex relationship analysis, such as social networks, recommendation systems, and fraud detection
- Neo4j is used by organizations to create knowledge graphs that help them connect and manage structured, as well as, unstructured data
- Model and analyze network dependencies, impact analysis and root cause identification
Conclusion
Open source databases have become the backbone of numerous large-scale applications and systems, including AI applications. Cost effectiveness, scalability, reliability, extensibility, and community support are some of the primary reasons to opt for an open source database (instead of a closed-source one).
We looked into the top 10 open source databases, but the choice of database depends on the team’s expertise and project requirements. The operational burden of managing databases can be completely avoided by opting for AceCloud Database-as-a-Service (DBaaS). It a fully managed, scalable, and secure cloud database platform that simplifies deployment, operations, and performance management for modern applications.

