Nemotron-3-Nano vs Mistral Small Models is a decision you face when agentic inference must be fast, predictable and affordable on GPUs. If p95 latency spikes or KV-cache growth squeezes concurrency, your serving cost per task can climb quickly.
McKinsey reports that 62% of organizations are already experimenting with AI agents, which increases pressure to quantify serving efficiency.
In agent loops you pay for retries, tool calls and long sessions, however tokens per second alone misleads you.
Nemotron-3-Nano-30B-A3B can emit a reasoning trace before its answer, and you can disable it to reduce latency. Its hybrid MoE stack has roughly 30–32B total parameters (31.6B total parameters in NVIDIA’s report) and activates about 3.5–3.6B parameters per token thanks to sparse MoE routing, which can lower effective compute and raise throughput.
Mistral Small 3.1 takes a dense latency-focused path with an Apache 2.0 license, multimodal inputs and a 128k context window.
This guide shows you how to compare throughput, p95 latency, KV-cache growth and tool-call correctness.
What is Nemotron-3-Nano-30B-A3B?
Nemotron-3-Nano-30B-A3B is an NVIDIA large language model trained from scratch and intended to handle both reasoning-heavy and straightforward tasks with a single architecture. When it answers a prompt, it can first produce an internal reasoning trace and then output the final response.
You can control this behavior using a flag in the chat template. If you disable the reasoning trace, the model returns only the final answer, which can reduce output length and latency, though it may slightly lower accuracy on more difficult prompts.
If you keep reasoning enabled, the model typically produces stronger final solutions for complex queries.
Key features and capabilities
- Hybrid architecture: Combines Mamba-2 with Transformer attention and sparse MoE layers, which increases capacity without activating most parameters.
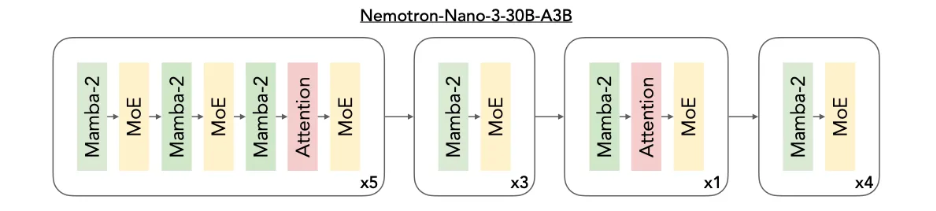
Image Source: NVIDIA
- Efficient inference: Roughly 30–32B total parameters with about 3.5–3.6B active per forward pass, which improves throughput by activating only a small subset of experts per token.
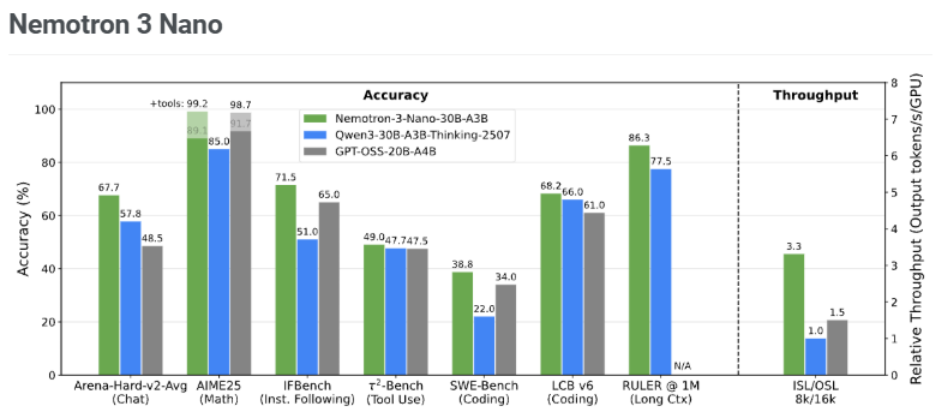
Image Source: NVIDIA
- MoE routing details:128 routed experts with top-6 activated per token, plus 1 shared expert applied to all tokens.
- Massive context window:NVIDIA’s technical report describes support for up to ~1M tokens, but most current deployments expose smaller limits (for example, ~256k context in typical Nemotron-3-Nano configs or Bedrock listings) due to VRAM and latency constraints.
- Advanced reasoning controls: Supports toggling reasoning traces on/off and setting a ‘reasoning budget’ (for example via model-specific parameters such as reasoning / enable_thinking and reasoning_budget in templating APIs), allowing the model to emit structured reasoning traces before final answers on difficult tasks.
- Native tool calling: The model is trained to emit function- / tool-calling friendly JSON structures (as exposed in platforms like Bedrock), which simplifies agent wiring when combined with runtimes that enforce tool schemas.
- Open and accessible: Released with open weights via NVIDIA channels, including Hugging Face distribution.
- High performance: Reports up to 3.3× throughput gains versus similarly sized open models in a specific H200 serving setup.
What is Mistral Small 3.1?
Mistral Small 3.1 is a versatile model that supports common generative AI workloads such as instruction following, chat-based assistance, image understanding and function calling. It can serve as a practical base model for both enterprise deployments and consumer applications.
Image Source: Mistral
Key features and capabilities
- Lightweight deployment: You can run Mistral Small 3.x on local hardware in practice, typically on a single high-memory GPU (≈55 GB VRAM for bf16/fp16 at full 128k context) or smaller GPUs when you combine quantization with a reduced context window.
- Fast conversational responses: It fits virtual assistants and other experiences where quick, accurate replies improve usability.
- Low-latency function calling: It can execute function calls quickly inside automated pipelines and agent workflows.
- Domain specialization through fine-tuning: You can fine-tune it for specific domains to improve precision in areas like legal workflows, clinical documentation support, and technical support.
- Strong base for downstream reasoning: The open-source community frequently builds reasoning-tuned variants on top of Mistral Small, such as DeepHermes 24B. To support similar customization, Mistral releases both base and instruct checkpoints for Mistral Small 3.1.
What changed in Mistral Small 3.2?
Mistral Small 3.2 is positioned as a production-oriented refinement of the Small 3.x line, with emphasis on agent behavior. It focuses on improved instruction following, fewer repetition errors, and a more robust function calling template.
That matters for agents, since repetition loops and invalid structured outputs often drive retries and cost.
If your bottleneck is tool-call correctness and schema reliability, 3.2 is the version to test first. Additionally, if you serve high concurrency, reduced looping can stabilize p95 latency across multi-step workflows.
Nemotron-3-Nano vs. Mistral Small Models – The Difference
Here is a side-by-side comparison table that you can use to map each model’s architecture to throughput, p95 latency, KV-cache growth and tool-call accuracy.
| Factors | Nemotron-3-Nano-30B-A3B | Mistral Small models (3.1 / 3.2) |
|---|---|---|
| Core efficiency lever | Sparse MoE + hybrid Mamba-Transformer reduces compute per token by activating fewer weights. | Dense Transformer tuned for low latency, simpler execution path per token. |
| Active vs total parameters | 31.6B total, ~3.2B activated per forward pass (3.6B incl. embeddings). | 24B dense (all parameters participate each token). |
| MoE routing detail | Activates 6 of 128 routed experts per token, plus 1 shared expert. | Not applicable (dense). |
| Long-context ceiling | Supports up to 1M tokens in the report. | Supports 128k tokens. |
| Hosted context limits | HF notes default configs often use 256k due to VRAM needs, and Bedrock lists 256k. | Typical hosted limit stays 128k. |
| Reasoning controls | Includes reasoning on/off and reasoning budget control, plus reasoning traces used in training. | No equivalent “reasoning budget” control is called out in the model cards. |
| Tool calling and structured output | Bedrock listing calls out native tool calling, and NVIDIA positioning targets agentic tool use. | Model card highlights native function calling and JSON output, and 3.2 improves function-calling template robustness. |
| Repetition and infinite loops | Report focuses on agentic training and benchmarks, but repetition reduction is not the headline claim. | 3.2 explicitly targets fewer repetition errors and fewer infinite generations. |
| Vendor-published throughput evidence | Reports up to 3.3× throughput vs Qwen3-30B-A3B-Thinking-2507 and 2.2× vs GPT-OSS-20B in an 8K in / 16K out test on single H200 with FP8. | Public messaging and reference benchmarks emphasize low latency and speed. For example, some published tests report around 150 tokens/s on high-end GPUs for chat workloads, but actual throughput depends on hardware, precision and decoding settings. |
| Weight memory footprint (bf16/fp16) | Not stated as a single “GB number” in the report, and MoE can shift memory tradeoffs by implementation. | HF model card notes ~55 GB VRAM for bf16/fp16 serving. |
| Quantization posture | NVIDIA reports FP8 PTQ for higher throughput with minimal loss in accuracy, and releases FP8 checkpoints. | Commonly served with vLLM, and many teams use lower precision or quantized variants in practice. |
| Licensing and governance | NVIDIA Nemotron Open Model License (not Apache). | Apache 2.0 for 3.1 and 3.2, simpler for many enterprise compliance paths. |
| Best-fit workloads | Long-horizon agent simulations, long-context experiments, throughput-focused batch or long generation scenarios. | Latency-sensitive orchestration loops, structured tool calling, production assistants with strict output format needs. |
Key Takeaway:
- Choose Mistral Small models when you need consistently low p95 latency, predictable dense serving, and reliable function calling with fewer repetition loops at 128k context.
- Choose Nemotron-3-Nano when throughput per GPU matters most, and sparse active-parameter compute can deliver real gains on your serving stack.
- In either case, you should validate cost per successful task under concurrency by measuring KV-cache growth, tail latency, and tool-call correctness.
Deployment Sizing Checklist for Infra Leads
Use this checklist when you size GPUs for production agents:
- Weights footprint: Confirm weight memory at your precision and reserve additional headroom for kernels and fragmentation.
- KV-cache growth: Estimate worst-case KV-cache at your context window and output limits, then scale for concurrency.
- Admission control: Enforce max context, max output tokens and step timeouts to protect p95 latency.
- Quantization validation: Re-test function calling and JSON validity after quantization, since formatting errors cause costly retries.
- Sequence mix: Benchmark short-turn tool loops and long-generation tasks separately, since winners can differ by traffic shape.
Ready to Run Agentic Inference Faster and Cheaper?
Nemotron-3-nano vs mistral small models is not a theoretical debate once you run agentic workflows under concurrency. You should validate the winner using cost per successful task, p95 latency, KV-cache growth and tool-call correctness across your real prompt mix.
If you need low tail latency and stable structured outputs, Mistral Small often fits better. If you want sparse compute efficiency and long-context experimentation, Nemotron-3-Nano can deliver stronger throughput on the right stack.
AceCloud helps you test both paths quickly on NVIDIA GPU instances, including on-demand and Spot options, plus managed Kubernetes when you need predictable scaling.
You can run side-by-side harness tests, tune quantization and right-size VRAM headroom without blocking your team. Explore AceCloud GPUs and start benchmarking with your agent harness today.
Frequently Asked Questions
It depends on your bottleneck. If you are compute-limited, Nemotron’s sparse active-parameter design and reported throughput advantages can help. If you are latency or reliability-limited, Mistral Small’s latency focus and 3.2’s repetition and function-calling improvements may reduce retries and cost per successful task.
In practice, you pick based on memory and tail latency. Mistral Small is explicitly positioned for local deployment and low-latency workloads but note bf16/fp16 memory needs around ~55GB for 3.2. Nemotron can be efficient per token, but long context settings can increase VRAM requirements quickly.
Look for suites that stress tool use and long-horizon behavior: SWE-bench (real issues), OpenHands harnesses, tau-bench (tool-agent-user policy following), IFBench (verifiable constraints) and RULER (long context). Then validate with your own harness because your tools and policies are the real test.
NVIDIA’s model card states the model is “ready for commercial use,” and NVIDIA’s Open Model License confirms commercial usability and derivative works terms. Always review licensing for your distribution and compliance needs.
Mistral Small 3 is released under Apache 2.0 per Mistral’s announcement, which is a common permissive license for commercial use and redistribution.