
Containers isolate applications and dependencies, which improves portability and release cadence across environments. However, orchestration is required to schedule containers, handle failures and expose services reliably. Kubernetes emerged to solve these needs through declarative APIs and reconciliation.
At a high level, the Kubernetes control plane maintains desired state, schedules workloads and makes global decisions. To dive in, you should first understand its components to predict behavior during failures and upgrades. In this explainer, you can learn the components, common architectures and an end-to-end flow from request to running Pods.
What is the Kubernetes Control Plane?
The control plane is the set of processes that expose the Kubernetes API, persist configuration and run control loops. These processes accept your desired state as objects, store them, then reconcile differences against observed cluster state.
(Source: Kubernetes)
You should view it as a continually running system, not a one-time scheduler. The design enables self-healing because controllers act whenever drift occurs. The control plane does not run user application containers. Worker nodes form the data plane that runs Pods and serves traffic.
Managed offerings such as EKS, GKE, AKS or GPU-focused clouds like AceCloud handle upgrades, availability and patching, which reduces undifferentiated toil. Teams still manage nodes and workloads, which preserves flexibility with lower operational overhead.
Recent reports observed 73 percent of cloud-hosted clusters used EKS, AKS, or GKE. This supports the conclusion that more than half of users rely on at least one managed service.
Note: Kubernetes use “master” for control hosts, although modern terminology uses “control plane node.” Control plane nodes are typically tainted to prevent regular workloads from scheduling there.
How is the Kubernetes Control Plane Architected in a Modern Cluster?
You can model the control plane logically as one system, then deploy it across several machines for resilience.
Logical view vs physical deployment
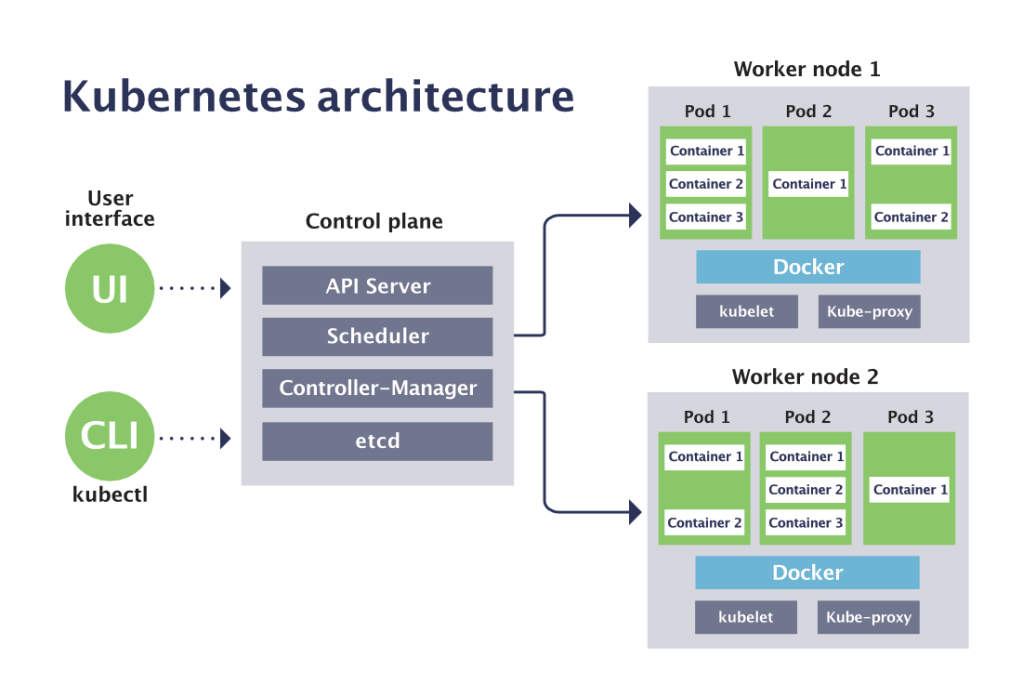
Logically, each cluster has one control plane that exposes the API and runs controllers and the scheduler. Physically, you deploy multiple kube-apiserver instances, controller managers, schedulers, and an etcd cluster. These processes collaborate through well-defined interfaces and consistent storage. You should separate concerns cleanly to simplify upgrades and failure handling.
High availability and multi-node control planes
Production clusters typically run three or five control plane nodes to reach quorum and survive failures. Etcd members are deployed in odd numbers to tolerate member loss without losing quorum.
Control plane nodes are tainted to avoid scheduling user Pods, which preserves resources for reconciliation. A load balancer fronts kube-apiserver to present a stable endpoint and distribute traffic across healthy servers.
On-premises, cloud, and GPU cloud examples
On premises, your platform team operates every control plane component and manages backups and failure domains. In managed services, the provider operates these components while you focus on nodes, networking and policies.
GPU-first clouds such as AceCloud pair managed control planes with GPU worker pools for training and inference, while delivering a 99.99* percent uptime SLA for core networking. This combination supports AI workloads that require predictable availability.
What are the Core Components of the Kubernetes Control Plane?
You should recognize each component’s role, because troubleshooting depends on knowing where the state moves.
1. kubeapiserver
Kube-apiserver is the front end for all Kubernetes operations and the single-entry point for API requests. It authenticates and authorizes requests, applies admission controls, and then persists objects to storage. You can scale it horizontally behind a load balancer to improve throughput and resilience during traffic spikes.
2. etcd
Etcd is the consistent key value store that holds cluster state, including objects, configuration, secrets and status. Because it is the source of truth, you should implement regular, tested backups and practice restore procedures. Etcd tolerates member failures based on quorum math, which guides the choice of three or five members in production.
3. Kube scheduler
The scheduler watches for unscheduled Pods and assigns them to nodes using scoring based on resources and constraints. It considers CPU and memory requests, labels, affinity and anti-affinity, taints with tolerations and topology spread. You can tune policies to prefer GPU nodes or isolate latency-sensitive workloads, which improves utilization and reliability.
4. Kube controller manager
Kube controller manager runs many controllers, each responsible for a resource type through a control loop. Examples include the node controller, deployment controller, namespace controller and service account controller. Controllers compare desired state from etcd to observed state and then act to close gaps. You should monitor controller lag and reconcile errors to detect systemic issues early.
5. Cloud controller manager
In cloud environments, the cloud controller manager integrates Kubernetes with provider APIs for nodes, load balancers and volumes. This separation allows faster cloud feature delivery without changing core Kubernetes. You can replace or upgrade provider integrations independently, which simplifies lifecycle management.
How does the Kubernetes Control Plane work?
You can follow a request from submission to running containers to understand where to observe and measure.
(Source: Sensu)
From kubectl apply to persisted desired state
A user or CI pipeline submits a Deployment through kubectl or the REST API. Kube-apiserver authenticates the caller, authorizes the request, runs admission controls, and then writes the validated object into etcd. You should enforce encryption at rest for sensitive resources through a KMS plugin, which protects stored secrets.
Controllers reconciling the desired state
The deployment controller notices the new Deployment and creates or updates a ReplicaSet. It then ensures that the requested replica count is satisfied by creating Pods as needed. Controllers continually react to events such as node loss or Pod restarts, which preserves service level objectives without manual intervention.
Scheduling and node execution
The scheduler selects a node for each unscheduled Pod using scoring and filters. Kubelet on the chosen node starts containers through the runtime, mounts volumes and configures networking. Kubelet then reports status back to the API server, which updates object status fields for observers and automation.
Continuous feedback loop
The control plane never stops reconciling, which keeps the cluster self-healing. You should collect logs and metrics from apiserver, controller manager, scheduler and etcd to diagnose performance or reliability problems before they become incidents.
Why Control Plane Design Matters for AI or GPU Workloads?
You can reduce risk and cost for AI training or inference by hardening the control plane first.
1. Impact on uptime and incident blast radius
If the control plane becomes unavailable, you cannot deploy, scale or heal workloads even if some Pods still run. Misconfigured etcd, apiserver or controllers can trigger cluster-wide impact because reconciliation touches many resources. You should isolate changes, validate backups and test failure modes routinely.
2. Performance and scale considerations
High API traffic from CI pipelines, operators and autoscalers can saturate the control plane. You can mitigate risk by scaling apiserver replicas, tuning admission controllers and applying request throttling. Additionally, you should profile controllers and reduce churn in object updates to maintain headroom during peaks.
3. AI, ML, and GPU-heavy workloads
GPU nodes are expensive, which amplifies the cost of control plane instability. Efficient scheduling of GPU Pods requires healthy API servers and responsive controllers, especially with large batch jobs. AceCloud compares Cloud GPU pricing for an 8× H100 80 GB cluster and claims 30 to 80 percent savings versus hyperscalers, heightening the financial value of uptime.
Deploy Managed Kubernetes with AceCloud
The control plane is the brain of Kubernetes, responsible for storing state, scheduling and continuous reconciliation. Components such as kube-apiserver, etcd, the scheduler and controller managers must be designed for resilience, monitored carefully and upgraded with discipline.
You should decide whether to self-manage or use a managed control plane, size control plane nodes and select three or five etcd members. Don’t know how to get started? Why not connect with Kubernetes experts at AceCloud and get all your queries resolved in a free consultation session? Connect today!
Frequently Asked Questions
It is the set of components that expose the Kubernetes API, store cluster state and run controllers and the scheduler that align actual state with desired intent.
The control plane makes decisions and stores configuration, while the data plane consists of worker nodes that run Pods and serve real traffic. You should keep them separated to reduce blast radius.
In services like EKS, GKE, AKS or AceCloud managed Kubernetes, the provider operates the control plane, including upgrades and availability, while you manage nodes and workloads.
Run three or five control plane nodes, deploy an HA etcd cluster, front API servers with a load balancer, back up etcd and test recovery regularly.










