
The Cloud Computing vs Big Data debate often shows up because one provides infrastructure while the other creates value from information. The difference between the two technologies is clear:
- Cloud platforms give you elastic compute, storage and managed services that you can provision when demand changes.
- Big data practices help you ingest, store and analyze large or fast data to support decisions in products and operations.
And the scale is hard to ignore, since Statista reports over nine billion emails sent every day. These technologies, though distinct, often overlap, empowering organizations to scale operations, enhance decision-making and drive data-driven strategies.
Let’s explore their architecture and applications and how they complement each other in shaping modern enterprises.
What are Cloud Computing and Big Data?
Cloud computing means you rent compute, storage and networking on demand, usually with usage-based pricing. This model matters because you can avoid large upfront purchases and scale capacity when workloads change. Cloud is a delivery model for infrastructure and platforms, including managed databases and analytics services.
Big data is “big” when volume, velocity or variety exceeds what a single server can reliably store and process. Big data is a set of methods and tools for ingestion, storage, processing and analysis at high scale.

| Aspect | Cloud Computing | Big Data |
|---|---|---|
| Architecture | Built on a network of remote servers hosted on the internet, following models like SaaS, IaaS or PaaS. | Comprises storage frameworks (e.g., Hadoop, NoSQL), data processing engines and analytics tools. |
| Usage and Applications | Used for scalable, flexible IT resources like virtual machines, storage, databases and software applications. | Focused on data collection, storage, processing and analytics, especially in fields needing extensive data analysis. |
| Scalability and Processing | Offers elastic scalability by adjusting resources based on demand, ideal for varying workloads. | Utilizes distributed computing for real-time analytics and rapid processing of large datasets. |
Note: Most traditional approaches break down because one machine hits limits in disk throughput, memory and parallel CPU execution. Modern-day distributed storage and compute tackle that problem by splitting data and work across multiple nodes.
How Cloud Computing Make Big Data Easier to Run at Scale?
Data workloads spike during batch ETL runs, historical backfills and model retraining cycles. With cloud computing, you get elastic capacity which helps you scale up for the spike, then scale down when the job finishes. This is also critical since vent-driven surges also happen during incidents, promotions or new product launches where logs and clicks jump.
Which cloud capabilities matter most?
- Separation of storage and compute matters because you can scale processing without copying the entire dataset.
- Autoscaling matters because it reduces manual intervention when workloads change across hours and days.
- Managed data services help because they offload patching, failover and routine operations from your team.
- Repeatable deployments with Kubernetes help because you can version infrastructure and reduce configuration drift.
Where do teams typically struggle?
However, there are two main issues that make it challenging to use cloud computing with big data.
- Cost control becomes difficult when clusters run 24/7, data copies multiply and teams create unmanaged environments.
- Governance makes life tough when identities, access rules and retention policies differ across accounts and regions.
Flexera findings highlight this pressure, with 84% citing cloud spend management as the top challenge. The same report notes that 27% estimated waste on IaaS and PaaS and budgets exceeded by 17% in surveyed organizations.
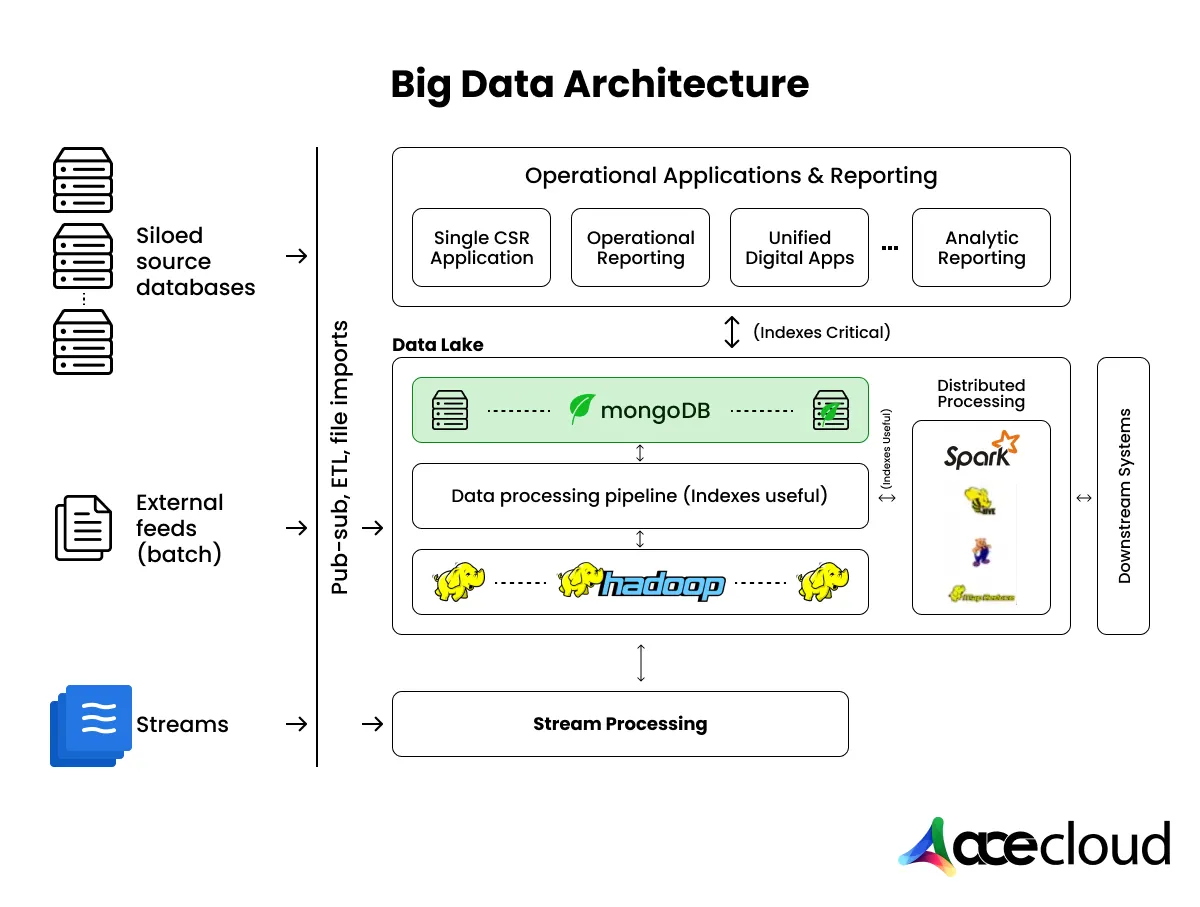
What a Cloud-based Big Data Pipeline Look Like?
Well, a cloud-based big data pipeline is a repeatable workflow that moves raw data into trusted datasets and then into decisions. Here are the different stages involved:
- Sources: Apps, logs, IoT devices and transactions generate the raw events you need to capture.
- Ingestion: Batch handles periodic loads, while streaming handles near real-time events and alerts.
- Storage: A lake stores raw and curated files, while a warehouse optimizes structured analytics queries.
- Processing: Distributed engines transform data, validate quality and compute aggregates for reporting.
- Serving: BI dashboards, APIs and ML features deliver results to people and systems that act on them.
- Governance: Access control, retention, lineage and audits reduce risk and keep data usable over time.
| Key Components | Cloud Computing | Big Data |
|---|---|---|
| Service Models | SaaS, PaaS, IaaS | Hadoop, Spark, NoSQL, Data Lakes |
| Resource Management | Virtualized Servers, Containers | Distributed Nodes, Data Clusters |
| Access | Web-based access | Primarily through data platforms |
Also Read: IaaS vs. PaaS vs. SaaS- What are the differences?
Where Cloud and Big Data Combination Create the Biggest Business Impact?
While their natures differ considerably, both cloud computing and big data have an extremely wide-ranging impact across sectors:
- Personalization and Segmentation: This improves relevance because you can target offers based on recent behavior and context.
- Predictive Analytics: The combosupports planning because forecasts use historical patterns and current signals to reduce guesswork.
- Real-time Monitoring: It reduces loss because alerts can catch fraud, outages and security events while they are still small.
- AI Readiness: It improves model reliability because governed and well-labeled data reduces training noise and bias.
- File Storage and Backup: Cloud providers such as Amazon S3 and Google Drive provide robust, elastic storage solutions wherein corporations can store enormous volumes of information without having to manage underlying hardware.
- Web Hosting: The use of cloud infrastructure hosting websites and applications makes it possible to ensure quite easy scalability with a large reduction of on-premises servers required for hosting those websites or applications.
- Distance Collaboration and Productivity: With Slack, Microsoft Teams or Google Workspace, teams can work remotely, share files and communicate in real-time from anywhere.
- Scalability and Data Processing: They are two most important features that would apply to cloud computing as well as big data because the technique is highly focused on today’s business environments.
| Applications | Cloud Computing | Big Data |
|---|---|---|
| Primary Use | Infrastructure & application delivery | Data analytics and insights |
| Common Platforms | AWS, Google Cloud, Azure | Hadoop, Apache Spark, MongoDB |
| Example | Google Workspace, Amazon S3 | Social media sentiment analysis, IoT monitoring |
How to map use cases to outcomes?
In our opinion, you should connect each use case to a measurable metric like conversion, churn, downtime or investigation time. That linkage matters because leaders fund outcomes, while engineers need clear acceptance criteria for delivery.
How to Choose a Cloud and Big Data Strategy?
The best way is to avoid design churn by deciding a few constraints first, then building only what the first use case requires. Here’s how you can do it:
- Start with latency needs, since real-time systems require different ingestion and serving than batch reporting.
- Next, estimate data growth and retention because storage design and partitioning depend on time horizons.
- Then, confirm compliance requirements because encryption, residency and audit controls can drive major platform choices.
- Finally, assess team maturity because a smaller team often benefits from managed services over self-managed clusters.
What rollout plan keeps it focused?
- Pick one high-ROI use case and define success metrics, data sources and expected refresh frequency.
- Build a minimal pipeline with ingestion, storage, processing and a single serving path, then automate deployments.
- Add governance basics early, including access roles, data quality checks and backup policies that match business risk.
- Scale to more domains only after cost controls and ownership models are working in the first domain.
Key Takeaways: Cloud Computing vs Big Data
Cloud computing and big data represent two sides of the same coin, each addressing unique challenges while complementing the other.
Cloud computing reduces friction because you can provision infrastructure quickly and use managed services for reliability. On the other hand, big data practices create value because you can turn high-scale, messy data into trusted datasets and actionable insights.
However, the best results happen when you design the pipeline, cost controls and governance together rather than treating them as add-ons. To make the best move forward, you should consult cloud experts at AceCloud using your free consultation session!
Frequently Asked Questions
No, cloud is how you consume infrastructure and platforms, while big data is how you process and analyze data at scale.
Yes, although scaling and operations are often harder because you must plan capacity, hardware reliability and upgrades yourself.
Not always, since many teams use Spark and SQL engines on cloud storage while keeping the same pipeline principles.
Batch ingestion into a lake, one processing job for curated tables, then a BI dashboard with basic access controls and backups.

Related Post










Get in Touch

Credits First!
- 24*7 Human Support
- Pay-as-you-go Pricing
- No Egress Cost
- Multi Tier Security