
Apache Kafka and RabbitMQ are both open-source messaging technologies. However, they are built for different jobs.
Kafka is a distributed commit log optimized for high-throughput event streaming and replay. RabbitMQ is a general-purpose message broker optimized for push delivery, protocol flexibility and workflow routing.
In Confluent’s cross-broker benchmark:
- Kafka hit ~605 MB/s peak throughput with low p99 ~5 ms at 200 MB/s load.
- RabbitMQ achieved very low latency (~1 ms) but only at a reduced ~30 MB/s load.
While Kafka is a distributed commit log optimized for real-time event streaming and high-throughput workloads, RabbitMQ offers a traditional messaging system designed for flexible routing, reliable delivery and traditional queue-based messaging use cases.
Kafka v/s RabbitMQ – What is the Actual Difference?
The main difference is that RabbitMQ is a message broker for low-latency task and request/reply routing with queues and rich routing patterns.
Whereas, Apache Kafka is an open-source streaming platform for building real-time data pipelines and streaming applications.
Compared to RabbitMQ, Kafka offers a more scalable, fault-tolerant and durable messaging system with extra features.
What is the Architectural Difference Between RabbitMQ and Kafka?
Producers or publishers are the applications that create and publish information, whereas consumers are applications that subscribe to and process the same data.
Kafka generally offers higher horizontal scalability and durable replay by design (retention + offsets). RabbitMQ offers protocol breadth and fine-grained delivery control and now includes Streams for retained logs when replay is needed. Most RabbitMQ designs expect queues to drain; most Kafka designs expect topics to retain.
RabbitMQ Architecture

Image Source: RabbitMQ
As similar to other message brokers, RabbitMQ receives messages from producers. Within the system, messages are received at an exchange, a virtual ‘post-office’, which routes messages onwards to storage buffers known as queues. Now, consumers can subscribe to these queues to pick up the latest data that arrives in the mailboxes.
Kafka Architecture
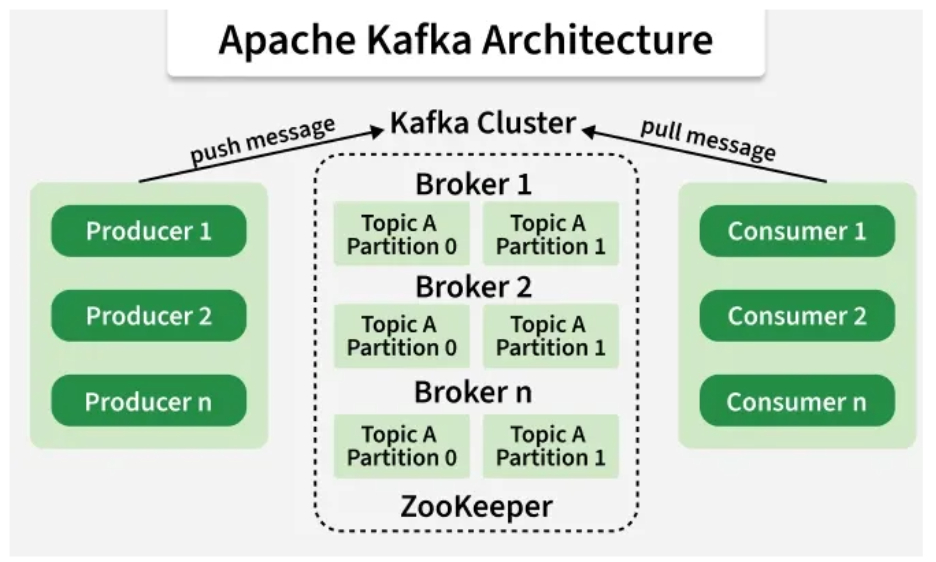
Image Source: GeeksforGeeks
In Kafka, producers and consumers are the same applications that publish and read messages in the queue without any regard for consumers.
| Dimension | RabbitMQ | Kafka |
|---|---|---|
| Delivery model | Push from broker to consumers; explicit acks and redelivery | Pull; consumers fetch and track offsets |
| Storage model | Queues (classic/quorum) designed to drain quickly; Streams for retained logs | Persistent, append-only log with retention by size/time |
| Ordering | Per-queue (retry & redelivery can affect perceived order); shard queues by key for stronger per-key order | Strong per-partition order; global order requires single partition or re-sequencing |
| Fan-out | Powerful routing (topic/direct/headers/fanout) to specific queues | Fan-out by having many consumer groups; each group reads independently |
| Replay | Classic queues: limited; Streams: yes | First-class via offsets and retention |
| Protocols | AMQP 0-9-1, STOMP, MQTT, AMQP 1.0 (plugins) | Native clients; Connect ecosystem for sources/sinks |
What are the Real-World Use Cases?
From high-throughput streams to low-latency brokers, see when Kafka or RabbitMQ fits your workload best in practice.
Apache Kafka
Apache Kafka is a distributed event streaming platform designed for high-throughput and real-time data processing. It includes Kafka Streams, a client library for building stream-based applications and microservices. Kafka is well-suited for systems that require scalability, fault tolerance and continuous data flows.
Recommended Use Cases
- High-throughput event streaming: Ingest clickstreams, IoT telemetry or payments at 100K+ events per second by partitioning topics and scaling consumers horizontally. “At least once” delivery with idempotent producers and keys ensures ordered processing per partition and safe retries during spikes.
- Stream history and replay: Kafka retains events for a configured window so new services can bootstrap from the log and existing ones can reprocess after bugs or schema changes. Replay by key preserves per-partition ordering while catching up to real time.
- Event sourcing: Represent every state change as an immutable event. Downstream projections rebuild current state and enable audit trails and CQRS patterns. Rolling back means reprocessing, and model migrations become new projections from the same facts.
- Stream processing pipelines: Compose real-time stages such as filter, enrich, join and aggregate using Kafka Streams or Flink. Windowed analytics and joins across topics produce low-latency outputs for alerts, features or caches while stateful processing keeps throughput predictable.
RabbitMQ
RabbitMQ is a message broker that supports multiple messaging protocols and patterns. It is effective in scenarios requiring low latency, flexible routing and support for legacy protocols.
Recommended Use Cases
- Asynchronous task handling: Use queues to offload CPU/IO heavy work such as image resizing, email dispatch and payment clearing to background workers. Web requests return instantly while workers scale horizontally and retry safely, smoothing bursts and isolating failures.
- Legacy protocol support: RabbitMQ speaks STOMP, MQTT and AMQP 0-9-1, making it a bridge between modern services and older systems or constrained devices. This enables incremental migration without rewriting clients.
- Customizable message delivery: Per-message options such as persistence, TTL, priorities, acks and dead-letter exchanges let you trade latency for durability. Choose at least once for critical workflows or transient, non-persistent messages for speed.
- Complex routing: Exchange types (direct, topic, headers, fanout) route messages to specific queues using keys and patterns. Implement tenant sharding, geo routing, selective broadcasts, rate-limited lanes or compliance-driven segregation.
- Multiple messaging patterns: Publish/subscribe, work queues and request/reply with correlation IDs are first class. You can unify event notifications, background job distribution and RPC-style calls on one operational backbone. Operational visibility improves.
How Do Performance Benchmark, Throughput and Latency Compare?
Kafka achieves high sustained throughput over a long period of time by using sequential disk I/O, batching, compression and partition parallelism across brokers. Accordingly, you can scale out read and write capacity by increasing partitions without breaking per-partition order.
RabbitMQ often delivers lower end-to-end latency for task queues and synchronous workflows because push delivery reduces coordination overhead.
Recently, backlog drained rates improved and memory pressure decreased for quorum queues during spikes. Nevertheless, results depend on payload sizes, replication factors, batch thresholds and network placement across zones.
You should benchmark with production-like parameters that include realistic message size distributions and batch settings.
Next, measure p50, p95 and p99 latency during sustained load with failover events and rolling upgrades.
Then, record catch-up behavior after induced backlogs because recovery time dominates perceived reliability during incidents.
Performance Benchmarking Comparison Table
| Feature | RabbitMQ(Mirrored) | Kafka |
|---|---|---|
| Peak Throughput (MB/s) | 38 MB/s | 605 MB/s |
| p99 Latency (ms) | 1 ms* (reduced 30 MB/s load) | 5 ms (200 MB/s load) |
Note: *When the throughput exceeds 30 MB/s, RabbitMQ latencies drastically deteriorate. Moreover, mirroring has a major effect at larger throughput, and only classic queues without mirroring can produce superior latencies.
Source: Confluent
Which Delivery and Ordering Guarantees Shift Your SLOs?
The fastest way to overspend is to pay for guarantees no one observes.
With RabbitMQ, delivery is at-least-once by default and you control acknowledgement explicitly. Ordering holds within a queue, but if you scale out a queue with multiple competing consumers, perceived order can change.
That is usually fine for task distribution and RPC-like patterns where independence across keys is expected. When ordering really matters, you shard queues by key and keep one consumer per shard.
Kafka is also at-least-once by default. Idempotent producers reduce duplicates during retries, and transactions enable exactly-once processing in supported topologies. Ordering is strong within a partition.
If your product needs global order, you must constrain partitioning or introduce a re-sequencing stage. Either reduces horizontal headroom. The practical test is external. If users cannot perceive cross key reorderings, do not pay for global ordering. Spend your budget where it moves external SLAs.
Can RabbitMQ and Kafka Coexist Effectively?
Yes, they often coexist in pragmatic architectures with clear boundaries.
You can place RabbitMQ on the transaction path for commands and jobs that need to push delivery and fine routing. And use Kafka as the event backbone for analytics, audit and model features where retention and replay matter.
Then, bridge with change capture from sources, dual writes with idempotency or translation consumers that publish queue traffic into topics. Consequently, you can phase migrations to proceed without breaking existing producers or consumers.
Decision Quick Sheet
| Criterion | Favors RabbitMQ | Favors Kafka |
|---|---|---|
| Primary goal | Low latency delivery and workflow control | Durable history and replay at scale |
| Consumption model | Push with acks and retries | Pull with offsets and retention |
| Ordering boundary | Per queue with retry side effects | Per partition with strict order |
| Fan-out pattern | Few consumers with selective routing | Many consumers with independent pace |
| Reprocessing need | Rare and ad hoc | Common and deterministic |
| Operational focus | Topology design and per-message control | Partitioning, storage and consumer lag |
Key Takeaway
When you’re evaluating Kafka vs RabbitMQ, you should start with your SLOs and the shape of your traffic. Use this guide to align each technology with your real workloads, then test them using production-like benchmarks.
If you want help turning a scaling architecture comparison into a clear plan AceCloud can partner with your team. We design cloud scaling strategies that balance throughput and latency and cost. We build auto scaling solutions with Kubernetes and KEDA.
We set up observability for consumer lag and queue depth and time to green. We handle migrations and coexistence patterns without downtime.
Ready to move from theory to an actionable roadmap? Book a free architecture review with AceCloud and ship a resilient platform with confidence today.
Frequently Asked Questions:
No. Kafka typically leads in sustained throughput while RabbitMQ often achieves lower per-message latency for task-oriented traffic.
It can approximate continuous delivery yet replay and multi-team reprocessing remain harder without offsets and retention.
Only within a partition. Global ordering requires single-partition keys which limit parallelism and reduce maximum throughput.
RabbitMQ is simpler for smaller footprints. Kafka fits large event backbones but introduces broader surface area across storage and coordination.
Often yes. Use RabbitMQ for commands and jobs and Kafka for events and analytics where retention and replay create shared value.







